



Azure confirma una incidencia global en su portal de gestión con fallos de acceso y funcionamiento intermitente en varios servicios
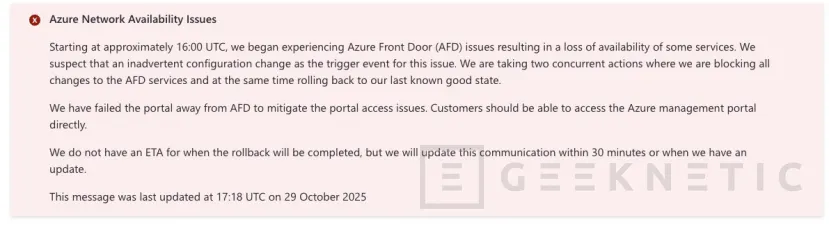
por Manuel NaranjoEl equipo de Azure Support ha comunicado una incidencia que afecta al acceso al portal de Azure y a operaciones de gestión relacionadas. La referencia oficial está en el tuit publicado por la cuenta de soporte y en la página pública de estado de Azure, donde se ha abierto el incidente y se va actualizando su evolución.
El fallo quedó identificado a las 16:00 UTC, lo que equivale a las 17:00 en España peninsular en la fecha de hoy. Ese matiz horario importa porque muchos equipos coordinan ventanas operativas y guardias de soporte con relojes locales; ubicar el inicio del problema en hora peninsular ayuda a reconstruir qué acciones se intentaron antes y después del punto de degradación.
Alcance e impacto operativo
Cuando falla el portal, no siempre se caen los servicios que ya están desplegados, pero sí se complica la gobernanza: visualizar recursos, escalar una máquina virtual, rotar una clave, ajustar reglas de red o, sencillamente, confirmar el estado de un clúster.
En la práctica, eso se traduce en equipos que ven su tiempo de respuesta alargado y en procedimientos internos que dependen de una consola gráfica que, por momentos, no responde o responde con latencia anómala. La página de estado de Azure encuadra estos episodios en la categoría de incidentes que afectan al plano de control: es decir, la capa que coordina y administra los recursos.
Ese tipo de degradación no arrastra necesariamente a los “workloads” en ejecución, pero sí eleva el riesgo operativo porque obstaculiza acciones manuales o automatizadas que se disparan desde la propia plataforma de gestión.
Qué dice Azure y cómo lo comunica
El mensaje del soporte de Azure es claro en la forma y prudente en el fondo: reconoce la incidencia, indica que el equipo está trabajando en la investigación y mitigación, y remite a la página de estado para seguir el detalle por regiones y servicios.
Este patrón de comunicación tiene dos virtudes. La primera, acotar la ansiedad: no especula con causas ni plazos mientras la ingeniería no cierra hipótesis. La segunda, aportar una única fuente autorizada con actualizaciones cronológicas, de modo que equipos técnicos, responsables de negocio y proveedores consulten el mismo reloj.
Cómo se siente desde dentro de un equipo
Más allá del titular, el impacto real aparece en los procesos cotidianos. Quien opera con infraestructura como código y “pipelines” de despliegue puede ver cómo ciertos pasos que invocan el plano de control fallan en cadena, aunque los servicios de fondo sigan emitiendo tráfico.
Quien depende del portal para acciones ad-hoc (revisar métrica de última hora, reiniciar un servicio puntual, abrir temporalmente un puerto), se encuentra con una pared sutil: la página carga, pero algunas operaciones no concluyen; o el “spinner” no se resuelve y hay que reintentar. En entornos regulados, esa incertidumbre obliga a documentar cada intento y a justificar por qué un cambio urgente se difirió, con el consiguiente desgaste de las guardias y del equipo de comunicación interna.
Qué puedes hacer mientras tanto
Aunque el origen esté del lado del proveedor, hay margen de maniobra. La experiencia demuestra que mantener vías alternativas de gestión reduce el tiempo muerto. Si el portal está degradado, Azure CLI y PowerShell suelen ofrecer una ruta más directa contra las APIs; conviene tener los comandos críticos preparados (alta de recursos, cambios de tamaño, reinicios controlados, obtención de estados) para no improvisar bajo presión.
Qué esperar a continuación
En este tipo de situaciones, Azure suele actualizar la cronología con hitos de investigación, mitigación provisional y recuperación completa, y posteriormente publica un análisis post-incidente que detalla causas y medidas preventivas.
Mientras llega esa aclaración, lo razonable es seguir el hilo oficial de Azure Support y la página de estado, registrar lo ocurrido en tu propio “runbook” y, si procede, ajustar ventanas de cambio. La hora de referencia (las 16:00 UTC del inicio) queda así fijada para cualquier auditoría o comparación de métricas de rendimiento y error.
El incidente anunciado por Azure Support y recogido en la página de estado no ha sido, por lo que consta, una caída de cargas de trabajo generalizada, pero sí una degradación sensible de la capa de gestión que afecta a la operativa diaria. A partir de ahí, la recomendación es pragmática: usar rutas alternativas de administración, limitar cambios no críticos, reforzar la comunicación interna y anotar todo para un análisis sosegado cuando llegue el informe oficial. La nube es infraestructura; y la infraestructura, cuando falla, se gestiona con método y con un reloj bien sincronizado.
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!







