Cómo organizar los Documentos de tu Empresa implementando un Gestor Documental con Docker e Inteligencia Artificial
por Raúl UnzuéMantener todos los documentos de tu Empresa organizados con un Gestor documental
En esta guía os vamos a enseñar cómo implementar un gestor documental para vuestra empresa con soluciones Open Source basadas en Linux, Docker y un Chatbot con IA.
El Gestor Documental que vamos a montar, será capaz de buscar en el contenido de ficheros DOCX, TXT, PDF e Imágenes, y darnos información sobre caracteres que aparecen en dichos ficheros.
Antes de comenzar el proceso, vamos a explicar qué es un Gestor Documental y qué importancia tiene en una empresa:
- Un gestor documental es como un gran armario digital súper organizado donde puedes guardar, buscar, y compartir tus documentos fácilmente.
En lugar de tener montones de papeles por todos lados o carpetas desordenadas en tu computadora, un gestor documental te ayuda a mantener todo en orden. Piensa en él como un software que:
- Organiza tus documentos: Puedes clasificarlos por categorías, etiquetarlos, o ponerles nombres fáciles de entender para encontrarlos rápido.
- Facilita la búsqueda: No necesitas pasar horas buscando un documento. Solo escribes una palabra clave, como el nombre del archivo, una fecha, o una etiqueta, ¡y aparece!
- Controla quién accede a qué: Si trabajas con otras personas, puedes decidir quién puede ver, editar o compartir ciertos documentos.
- Mantiene todo seguro: Protege tus documentos importantes con contraseñas, copias de seguridad y registros de quién hizo qué cambios.
- Digitaliza papeles físicos: Si tienes documentos en papel, puedes escanearlos y almacenarlos en el gestor para tener todo en un solo lugar.
En resumen, un gestor documental es como un asistente personal para tus archivos: lo organiza todo, lo hace fácil de encontrar, y lo mantiene seguro.
Un gestor documental local con inteligencia artificial puede transformar la manera en que tu empresa gestiona y consulta información. Este sistema centraliza los documentos, permite búsquedas avanzadas con IA, y asegura que los datos sensibles no salgan de tu red. Aquí aprenderás a implementar esta solución utilizando Docker, IA, Nextcloud y un servidor NAS. Al finalizar, tendrás un sistema robusto que garantizará la seguridad, escalabilidad y eficiencia en la gestión documental.
Instalación Máquina Virtual con GPU y requerimientos necesarios
Lo primero que tendremos que hacer es preparar nuestro entorno para poder instalar todos los componentes. En nuestro caso, vamos a usar una infraestructura Proxmox, en un host con GPU AMD, Debian 12 para sistema operativo principal, UNRAID como servidor NAS y Docker. Así que nos ponemos manos a la obra.
Paso 1. Actualización Sistema Operativo Debian 12
Lo primero que tendremos que hacer una vez instalada la máquina virtual es actualizarla con los siguientes comandos:
root@gestordocumental:~# apt update
Obj:1 http://security.debian.org/debian-security bookworm-security InRelease
Obj:2 http://deb.debian.org/debian bookworm InRelease
Obj:3 http://deb.debian.org/debian bookworm-updates InRelease
Leyendo lista de paquetes... HechoCreando árbol de dependencias... Hecho
Leyendo la información de estado... HechoTodos los paquetes están actualizados.
root@gestordocumental:~# apt upgrade -yLeyendo lista de paquetes... Hecho
Creando árbol de dependencias... HechoLeyendo la información de estado... Hecho
Calculando la actualización... Hecho
0 actualizados, 0 nuevos se instalarán, 0 para eliminar y 0 no actualizados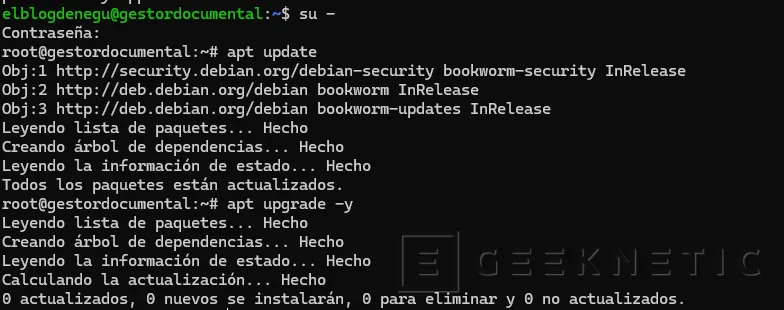
Una vez actualizada, instalaremos la tarjeta gráfica AMD para que la pueda utilizar y poder sacar la máxima potencia.
Paso 2. Instalación Driver GPU AMD en Proxmox
Tendremos que agregar la tarjeta gráfica en nuestra máquina virtual en Proxmox. Y una vez asignada, tendremos que instalar el driver necesario para Debian 12, de la siguiente forma:
elblogdenegu@gestordocumental:~$ wget https://repo.radeon.com/amdgpu-install/6.2.3/ubuntu/noble/amdgpu-install_6.2.60203-1_all.deb
--2025-01-20 15:52:41-- https://repo.radeon.com/amdgpu-install/6.2.3/ubuntu/noble/amdgpu-install_6.2.60203-1_all.deb
Resolviendo repo.radeon.com (repo.radeon.com)... 96.16.86.153, 96.16.86.159, 2a02:26f0:980:9::6010:56c8, ...
Conectando con repo.radeon.com (repo.radeon.com)[96.16.86.153]:443... conectado.
Petición HTTP enviada, esperando respuesta... 200 OK
Longitud: 16900 (17K) [application/octet-stream]
Grabando a: «amdgpu-install_6.2.60203-1_all.deb»
amdgpu-install_6.2.60203-1_al 100%[=================================================>] 16,50K --.-KB/s en 0s
2025-01-20 15:52:42 (93,7 MB/s) - «amdgpu-install_6.2.60203-1_all.deb» guardado [16900/16900]
elblogdenegu@gestordocumental:~$ sudo apt install ./amdgpu-install_6.2.60203-1_all.deb
[sudo] contraseña para elblogdenegu:Leyendo lista de paquetes... Hecho
Creando árbol de dependencias... HechoLeyendo la información de estado... Hecho
Nota, seleccionando «amdgpu-install» en lugar de «./amdgpu-install_6.2.60203-1_all.deb»
amdgpu-install ya está en su versión más reciente (6.2.60203-2044426.24.04).
0 actualizados, 0 nuevos se instalarán, 0 para eliminar y 0 no actualizados.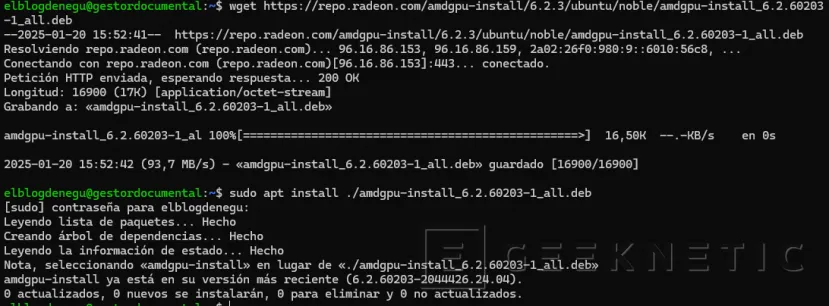
Paso 3. Validar Tarjeta Gráfica en Máquina Virtual
Validamos que vemos bien la tarjeta en la máquina virtual:
elblogdenegu@gestordocumental:~$ lspci | grep -i --color 'vga\|3d\|2d'
00:01.0 VGA compatible controller: Red Hat, Inc. Virtio 1.0 GPU (rev 01)
01:00.0 VGA compatible controller: Advanced Micro Devices, Inc. [AMD/ATI] Navi 24 [Radeon RX 6400/6500 XT/6500M] (rev c7)
Paso 4. Instalar Docker en Debian
Una vez actualizada y con la GPU conectada correctamente, necesitaremos instalar Docker en nuestro Debian 12. Lo haremos de la siguiente forma:
root@gestordocumental:~# apt install -y docker.io docker-compose
root@gestordocumental:~# systemctl enable docker
Synchronizing state of docker.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable docker
root@gestordocumental:~# systemctl start docker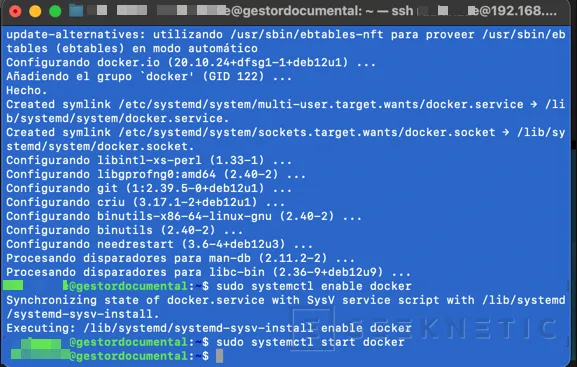
Validamos versiones:
root@gestordocumental:~# docker --version
Docker version 20.10.24+dfsg1, build 297e128
root@gestordocumental:~# docker-compose --version
docker-compose version 1.29.2, build unknownPaso 5. Configurar Share en el Servidor NAS UNRAID
Para poco sirve un gestor documental si no tenemos ficheros que indexar. En nuestro caso, usaré un NAS con UNRAID para crear un share y compartirlo vía CIFS.
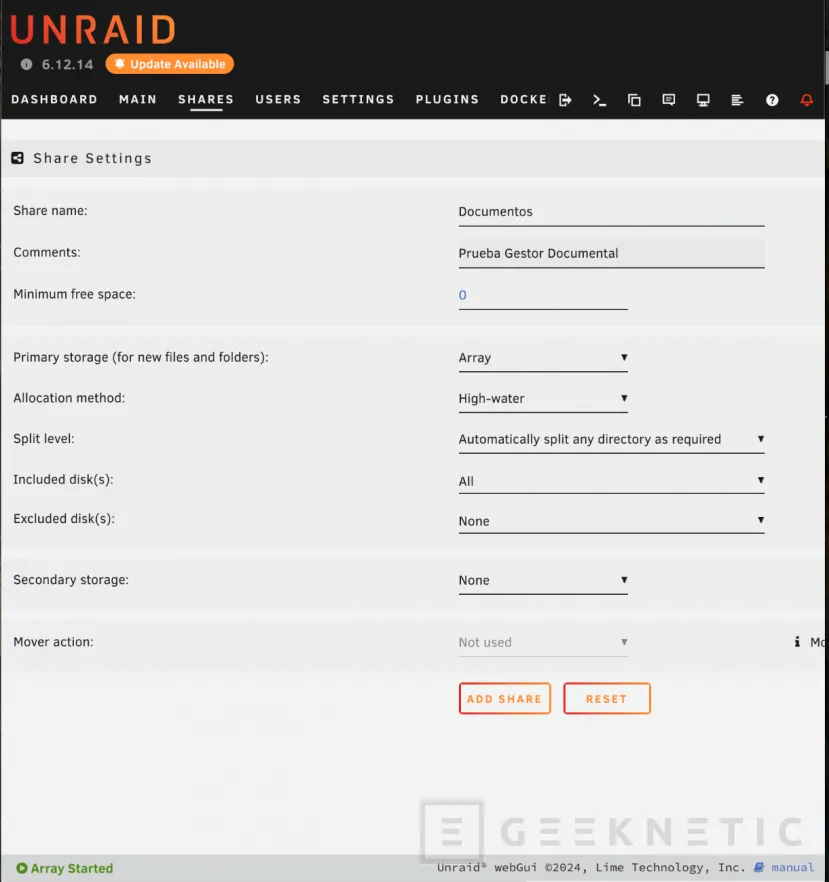
Para crear un Share en un UNRAID seguiremos los siguientes pasos:
- Accede al panel de tu NAS.
- Crea un share llamado Documentos y asigna permisos para lectura/escritura.
- Configura el acceso vía SMB:
- Por ejemplo, la ruta del share será //
/Documentos.
- Por ejemplo, la ruta del share será //
Paso 6. Montar Share CIFS en Debian 12
Con todo preparado en UNRAID necesitaremos montar el recurso en nuestra máquina virtual para revisar si tenemos permisos.
- Creamos un directorio para montar el NAS y dar permisos a ww-data:
sudo mkdir -p /mnt/nas/documentossudo chown -R www-data:www-data /mnt/nas
sudo chmod 755 -R /mnt/nas- Montamos el share con las credenciales del NAS :
sudo apt install cifs-utils psmisc
sudo mount -t cifs -o username=nas_user,password=nas_password ///Documentos /mnt/nas/documentos - Verificamos el montaje:
ls /mnt/nas/documentos
Con todo esto, ya tenemos todo preparado para ir instalando los componentes de nuestro Gestor Documental.
Instalar NextCloud bajo Docker
El primer componente de nuestro Gestor Documental va a ser NextCloud. NextCloud actuará como la base para gestionar, almacenar y compartir documentos, mientras el chatbot documental facilitará la búsqueda y recuperación de información.
Dispone de una interfaz amigable y la posibilidad de integración con múltiples soluciones, lo que hará que podamos avanzar en la evolución de nuestro Gestor Documental relativamente fácil.
Aunque está en el mismo proyecto, lo gestionaremos en nuestra máquina virtual es sus propios directorios por la importancia que tiene.
Creamos un archivo docker-compose.yml en una carpeta dedicada a NextCloud. Primero generamos la carpeta:
mkdir /mnt/nextcloudcd nextcloudAhora el fichero:
sudo nano docker-compose.yml Con el siguiente contenido:
version: '3.8'services: nextcloud: image: nextcloud
container_name: nextcloud ports: - "8080:80" volumes:
- /mnt/nas:/var/www/html/data
- ./nextcloud_config:/var/www/html/config
#user: “www-data:www-data” # UID y GID de www-data restart: always db:
image: mariadb container_name: nextcloud_db environment:
MYSQL_ROOT_PASSWORD: rootpassword MYSQL_DATABASE: nextcloud
MYSQL_USER: nextcloud MYSQL_PASSWORD: nextcloudpassword volumes:
- ./db_data:/var/lib/mysql restart: alwaysEn nuestro caso, que queremos montar un recurso CIFS, entraremos al contenedor Docker e instalaremos el cliente de “smbclient”. Lo haré con los siguientes comandos (para salir de la gestión del contenedor escribimos “exit” al terminar):
docker exec -it nextcloud /bin/bash
root@gestordocumental:~/nextcloud# docker exec -it nextcloud /bin/bash
root@6448b9e89446:/var/www/html# apt update && apt install smbclient
Desplegar Contenedores Docker
NextCloud se montará con dos contenedores, uno gestiona la parte web y otro la base de datos. Desplegamos los contenedores de la siguiente forma:
sudo docker-compose up –d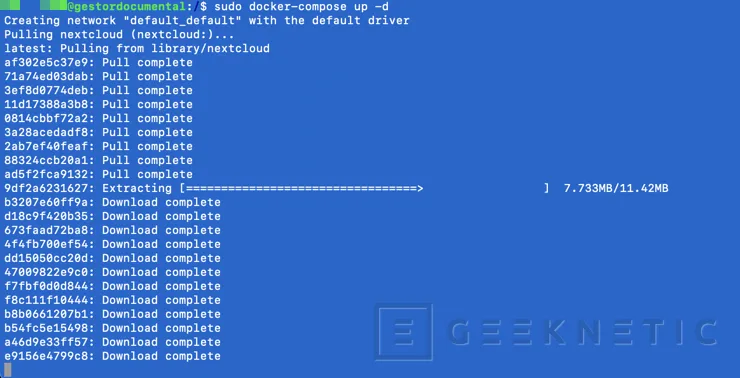
Y validamos con el siguiente comando:
sudo docker ps
Post-Instalación NextCloud
Accedemos a NextCloud desde un navegador:
- URL: http://IP-MAQUINAVIRTUAL
:8080.
Configuramos la base de datos usando las credenciales de MariaDB (nextcloud). Para entornos de producción o de alta carga sería importante usar un servidor dedicado de base de datos y no mantener todo en el mismo host.
- Pulsamos “Instalar”
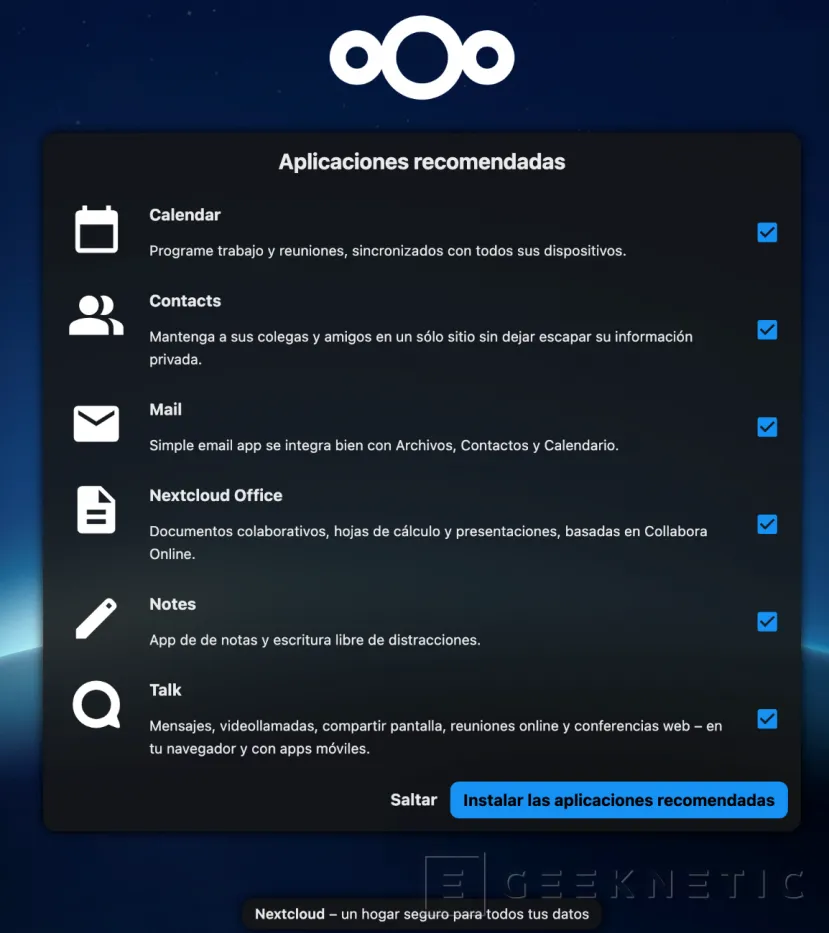
Pulsamos “Instalar aplicaciones recomendadas”. Se instalarán los complementos básicos de NextCloud. Posteriormente tendremos la posibilidad de instalar muchos más:
Instala la app "External Storage Support" en NextCloud:
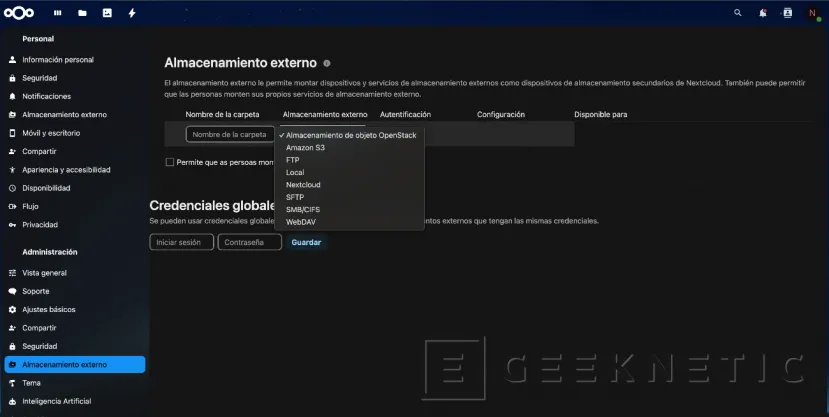
- Configura el almacenamiento externo:
- Tipo: SMB/CIFS.
- Dirección:
/Documentos. - Usuario/contraseña: Credenciales del NAS
Pulsamos en el icono del perfil de la parte superior, menú "Aplicaciones":
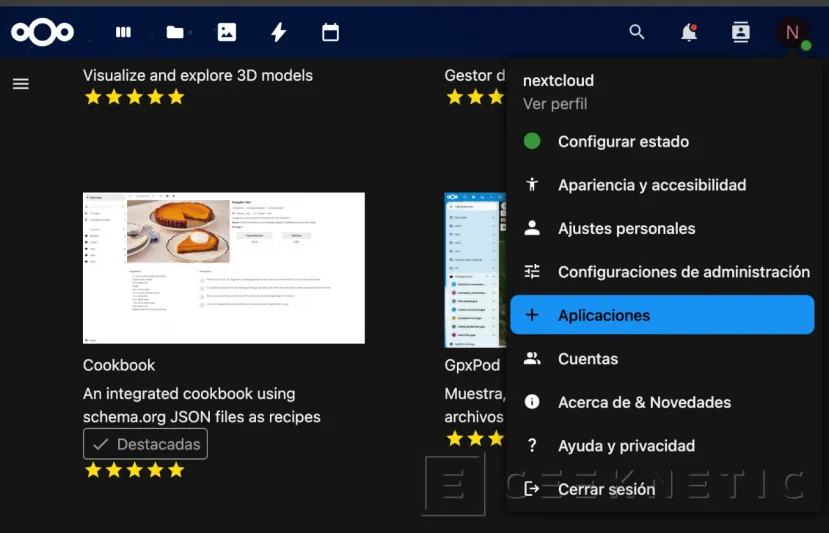
Buscamos la APP y pulsamos "Activar":
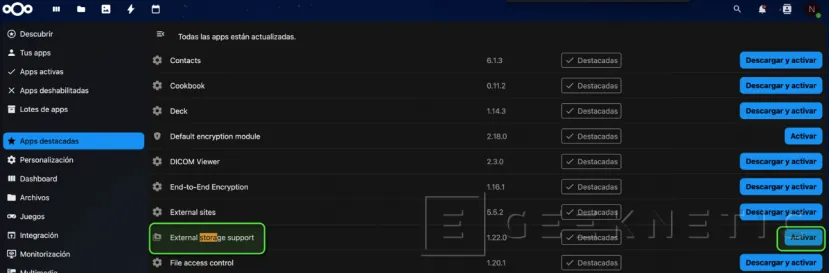
Vía consola, es probable que necesitemos instalar el componente de "smbclient" también en el Docker, así que lo instalamos antes de montar el Share:
elblogdenegu@gestordocumental:/$ sudo docker exec -u 0 -it nextcloud /bin/bash
root@70cb10497112:/var/www/html# apt update
Get:1 http://deb.debian.org/debian bookworm InRelease [151 kB]
Get:2 http://deb.debian.org/debian bookworm-updates InRelease [55.4 kB]
Get:3 http://deb.debian.org/debian-security bookworm-security InRelease [48.0 kB]
Get:4 http://deb.debian.org/debian bookworm/main amd64 Packages [8792 kB]
Get:5 http://deb.debian.org/debian bookworm-updates/main amd64 Packages [13.5 kB]
Get:6 http://deb.debian.org/debian-security bookworm-security/main amd64 Packages [241 kB]
Fetched 9301 kB in 1s (7812 kB/s)
Reading package lists... DoneBuilding dependency tree... Done
Reading state information... Done
1 package can be upgraded. Run 'apt list --upgradable' to see it.
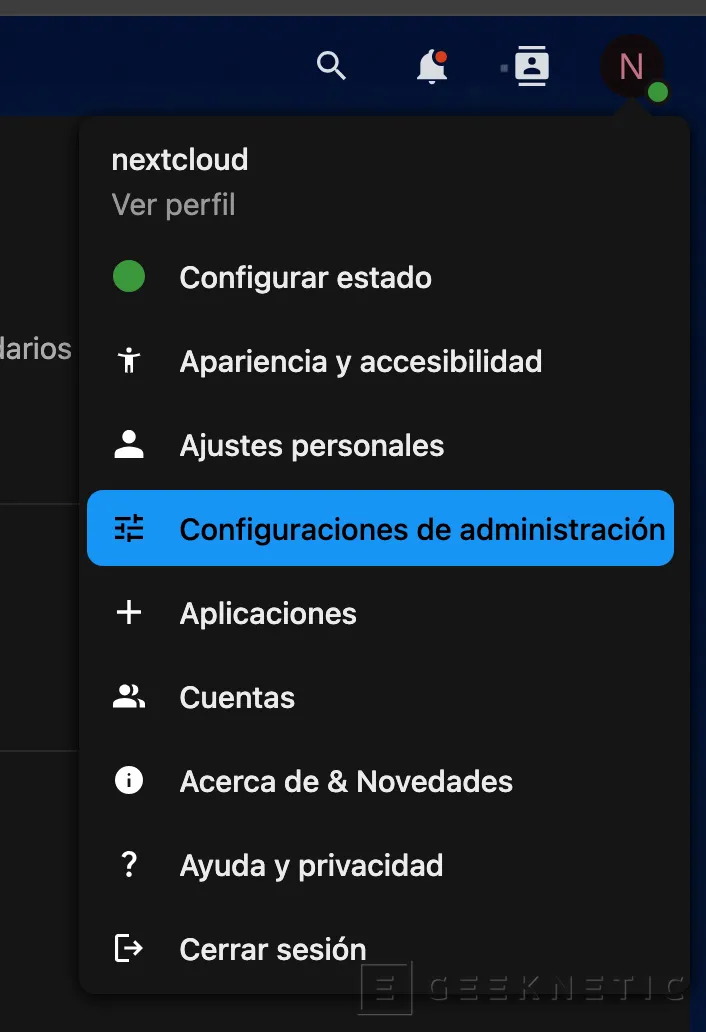
root@70cb10497112:/var/www/html# apt install smbclientSeguimos con la instalación. Vamos a configurar el recurso compartido en la gestión. Vamos arriba a la derecha al perfil, “Configuraciones de administración”:
Sección “Administración -> Almacenamiento externo”. Elegimos como Almacenamiento externo, como es nuestro caso, SMB/CIFS:
Introducimos IP o Nombre de nuestro NAS y el nombre del recurso compartido:
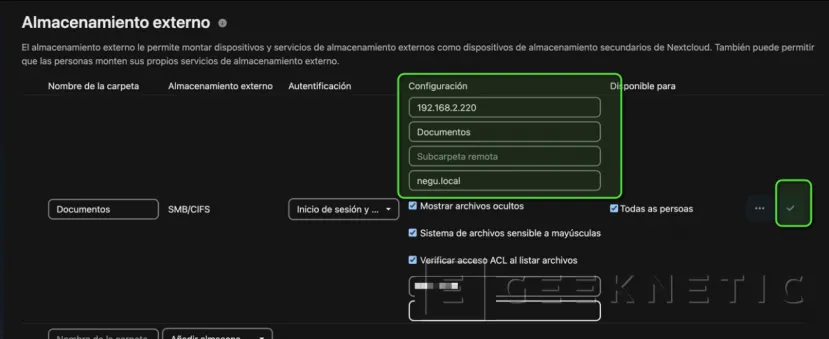
Nos pedirá las credenciales de administrador de NextCloud:
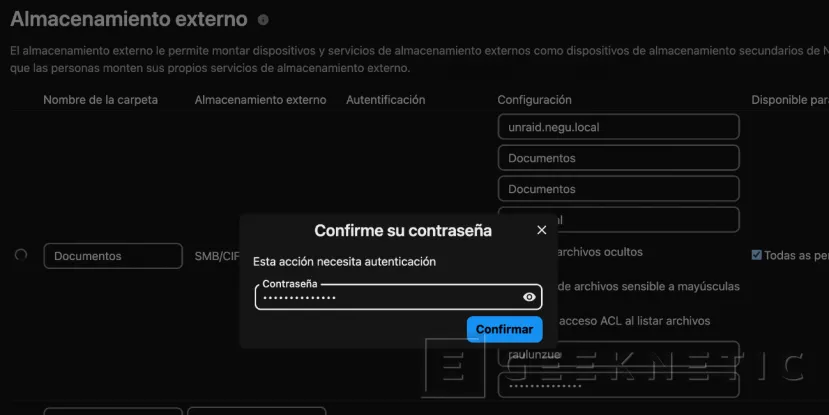
Si todo ha ido bien veremos un check verde:
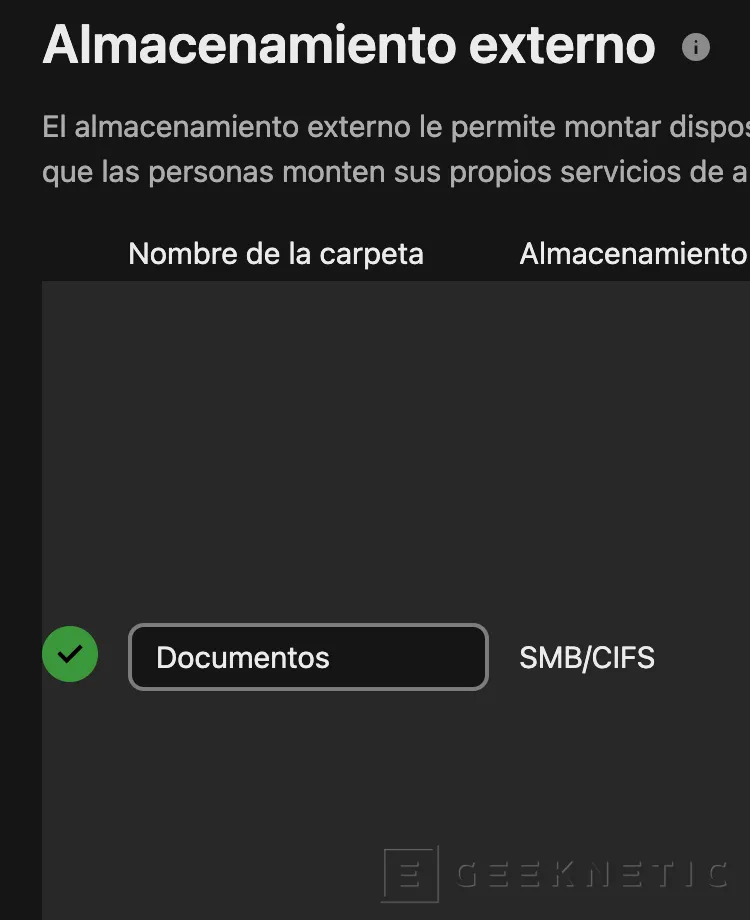
Ahora podemos revisar desde "Archivos -> Almacenamiento externo", la carpeta Documentos:
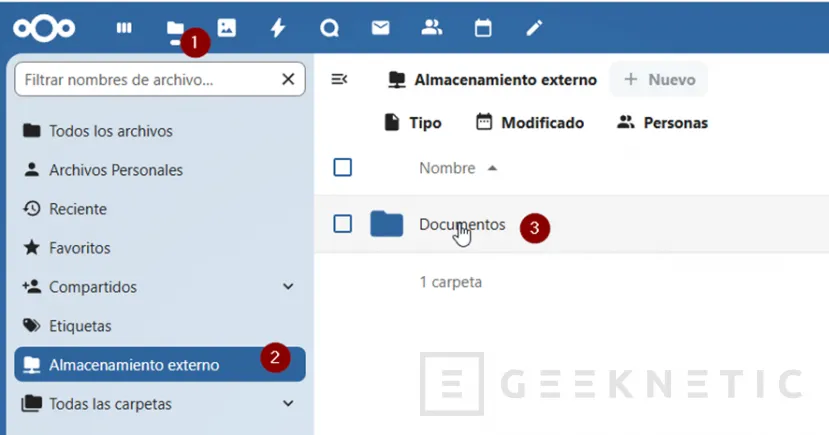
Con esto ya tenemos NextCloud instalado. Con todo preparado, empezamos a crear nuestro proyecto de gestor documental.
Directorios y Archivos del Gestor Documental
Para comenzar con el resto de contenedores que vamos a utilizar, vamos a generar una estructura de ficheros y directorios que nos ordenen el proyecto lo mejor posible, ya que es posible que tengamos que parametrizar nuestro gestor documental para adecuarlo a nuestro entorno.
Os dejo la estructura que vamos a generar:
/mnt/nas/nextcloud-chatbot/├── backend/
│ ├── Dockerfile # Backend Dockerfile
│ ├── requirements.txt # Dependencias del backend
│ ├── indexing_service.py # Servicio de indexación│ ├── app/
│ │ ├── __init__.py # Archivo de inicialización del backend
│ │ ├── main.py # Código principal de la API
│ │ └── config.py # Configuración general├── frontend/
│ ├── Dockerfile # Frontend Dockerfile
│ ├── nginx.conf # Configuración de Nginx
│ ├── index.html # Interfaz HTML
├── docker-compose.yml # Orquestación Docker
├── .env # Variables de entornoDescripción de los ficheros:
Backend:
- Dockerfile: Configura y construye la imagen Docker del backend.
- requirements.txt: Define las dependencias de Python necesarias, como
fastapi,uvicorn, y otras librerías específicas. - indexing_service.py: Contiene la lógica de indexación y búsqueda de documentos.
- app/: Carpeta principal del backend.
__init__.py: Archivo vacío que indica queappes un paquete Python.main.py: Implementa las rutas de la API del backend, como/search/y/reindex/.config.py: Archivo para almacenar configuraciones como rutas de acceso a documentos.
Frontend:
- Dockerfile: Configura y construye la imagen Docker para el frontend basado en Nginx.
- nginx.conf: Configura el proxy inverso para enrutar solicitudes entre el frontend y el backend.
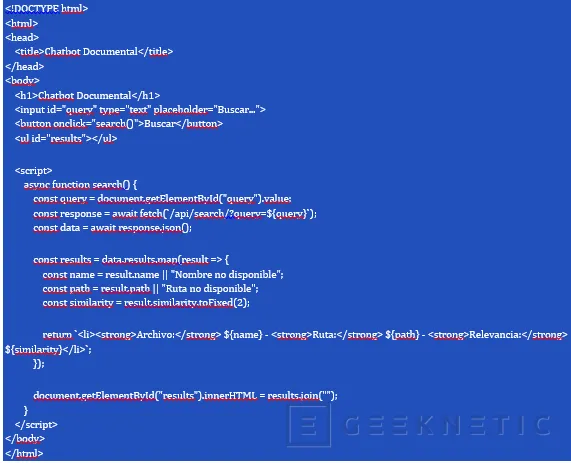
- index.html: Página principal del chatbot documental, con el formulario para búsquedas.
Proyecto raíz:
- docker-compose.yml: Define cómo interactúan los servicios de backend y frontend en contenedores Docker.
- .env: Variables de entorno utilizadas en el proyecto, como rutas de acceso y configuraciones sensibles.
Generamos los directorios e iremos creando fichero a fichero:
mkdir -p /mnt/nas/nextcloud-chatbot/{backend,frontend}
mkdir -p /mnt/nas/nextcloud-chatbot/backend/appcd /mnt/nas/nextcloud-chatbotContenido de los Archivos, Directorios y Rutas
Iremos generando los ficheros uno a uno.
1. Backend
1.1. /mnt/nas/nextcloud-chatbot/backend/Dockerfile
Creamos fichero:
nano backend/DockerfileCon el siguiente contenido:
FROM python:3.10-slimWORKDIR /app
# Instalar dependencias necesarias para FAISS y otras librerías
RUN apt-get update && apt-get install -y \ libopenblas-dev \
libomp-dev \ && apt-get clean# Instalar Tesseract OCR
RUN apt-get update && apt-get install -y tesseract-ocr libtesseract-dev
# Actualiza pip antes de instalar dependencias
RUN python -m pip install --upgrade pip
# Copiar requirements.txt y las dependenciasCOPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt# Copiar el código fuente
COPY . .EXPOSE 8000
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000", "--reload"]
1.2. /mnt/nas/nextcloud-chatbot/backend/requirements.txt
Creamos fichero:
nano backend/requirements.txtCon el siguiente contenido:
fastapiuvicornpython-docxrequestsfarm-haystack[all]fuzzywuzzy
scikit-learn # Reemplazo de sklearnnumpy<2.0pillowpytesseractPyPDF2
1.3. /mnt/nas/nextcloud-chatbot/backend/indexing_service.py
Creamos fichero:
nano backend/indexing_service.pyCon el siguiente contenido:
import osimport loggingfrom docx import Document
from haystack.document_stores import InMemoryDocumentStore
from haystack.nodes import EmbeddingRetriever
from haystack.pipelines import DocumentSearchPipelinefrom fuzzywuzzy import fuzz
from PIL import Imageimport pytesseractfrom PyPDF2 import PdfReader
# Inicializa el almacén de documentos y el recuperador de embeddings
document_store = InMemoryDocumentStore(embedding_dim=384)
retriever = EmbeddingRetriever( document_store=document_store,
embedding_model="sentence-transformers/all-MiniLM-L6-v2")
LOCAL_DOCUMENTS_PATH = "/mnt/nas/documentos"
# Configura los logs para depuraciónlogging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger(__name__) def get_local_files(): """
Obtiene una lista de todos los archivos admitidos en el directorio de documentos.
""" files = []
for root, _, filenames in os.walk(LOCAL_DOCUMENTS_PATH):
for filename in filenames:
if filename.endswith((".docx", ".txt", ".pdf", ".jpg", ".png")):
files.append(os.path.join(root, filename)) return files
def extract_content(file_path): """
Extrae contenido de archivos en diferentes formatos, incluyendo imágenes.
""" logger.debug(f"Procesando archivo: {file_path}") try:
if file_path.endswith(".txt"):
with open(file_path, "r", encoding="utf-8", errors="ignore") as f:
return f.read() elif file_path.endswith(".pdf"):
reader = PdfReader(file_path)
return " ".join(page.extract_text() for page in reader.pages if page.extract_text())
elif file_path.endswith(".docx"): doc = Document(file_path)
return " ".join(para.text for para in doc.paragraphs if para.text.strip())
elif file_path.endswith((".jpg", ".png")):
image = Image.open(file_path)
return pytesseract.image_to_string(image) except Exception as e:
logger.error(f"Error al procesar el archivo {file_path}: {e}")
return "" def index_files(): """
Lee los documentos e imágenes y los indexa, generando embeddings. """
logger.info("Iniciando proceso de indexación...")
document_store.delete_documents() # Limpia el índice actual
documents = [] for file_path in get_local_files():
content = extract_content(file_path)
if content.strip(): # Asegura que el contenido no esté vacío
logger.debug(f"Contenido extraído del archivo {file_path}: {content[:100]}") # Muestra los primeros 100 caracteres
documents.append({ "content": content,
"meta": {"name": os.path.basename(file_path), "path": file_path}
}) if not documents:
logger.warning("No se encontraron documentos para indexar.")
return document_store.write_documents(documents)
# Generar embeddings para todos los documentos indexados
logger.info("Generando embeddings para los documentos...")
document_store.update_embeddings(retriever)
logger.info(f"Documentos indexados: {len(documents)}") def search(query):
""" Busca documentos relevantes basados en la consulta. """
logger.info(f"Realizando búsqueda para la consulta: {query}")
pipeline = DocumentSearchPipeline(retriever)
results = pipeline.run(query=query, params={"Retriever": {"top_k": 10}})
# Si no hay documentos relevantes if not results["documents"]:
logger.info(f"No se encontraron resultados para la consulta: {query}")
return {"message": "No se encontraron resultados para tu búsqueda."}
# Priorizar coincidencias exactas en el nombre del archivo
exact_matches = [ doc for doc in results["documents"]
if fuzz.partial_ratio(query.lower(), doc.meta["name"].lower()) > 80
] if exact_matches:
logger.debug(f"Resultados exactos: {[doc.meta['name'] for doc in exact_matches]}")
return exact_matches
logger.debug(f"Resultados generales: {[doc.meta['name'] for doc in results['documents']]}")
return results["documents"]
1.4. /mnt/nas/nextcloud-chatbot/backend/app/main.py
Creamos fichero:
nano backend/app/main.pyCon el siguiente contenido:
from fastapi import FastAPIfrom indexing_service import index_files, search
app = FastAPI()@app.on_event("startup")async def startup_event():
index_files()@app.get("/search/")async def search_endpoint(query: str):
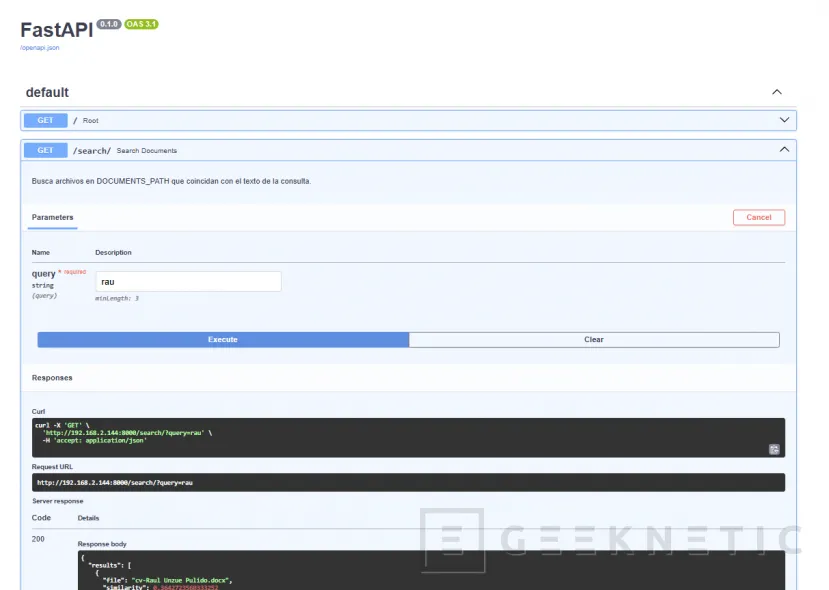
results = search(query) return { "results": [ {
"name": doc.meta.get("name", "Nombre no disponible"),
"path": doc.meta.get("path", "Ruta no disponible"),
"similarity": doc.score }
for doc in results ] }@app.get("/reindex/")
async def reindex_endpoint(): index_files()1.5. /mnt/nas/nextcloud-chatbot/backend/app/config.py
Creamos fichero:
nano backend/app/config.pyCon el siguiente contenido:
LOCAL_DOCUMENTS_PATH = "/mnt/nas/documentos"2. Frontend
2.1. /mnt/nas/nextcloud-chatbot/frontend/Dockerfile
Creamos fichero:
nano frontend/DockerfileCon el siguiente contenido:
FROM nginx:alpine# Copiar la configuración personalizada de Nginx
COPY nginx.conf /etc/nginx/nginx.conf# Copiar los archivos del frontend
COPY index.html /usr/share/nginx/html# Exponer el puerto para NginxEXPOSE 802.2. /mnt/nas/nextcloud-chatbot/frontend/nginx.conf
Creamos fichero:
nano frontend/nginx.confCon el siguiente contenido:
events { worker_connections 1024;}http { server { listen 80;
location / { root /usr/share/nginx/html;
index index.html; } location /api/ {
proxy_pass http://chatbot-backend:8000/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr; } }}2.3. /mnt/nas/nextcloud-chatbot/frontend/index.html
Creamos fichero:
nano frontend/index.htmlCon el siguiente contenido:
3. Docker Compose
3.1. /mnt/nas/nextcloud-chatbot/docker-compose.yml
Creamos fichero:
nano docker-compose.ymlCon el siguiente contenido:
version: "3.8"services: chatbot-backend: build: context: ./backend
volumes: - /mnt/nas/documentos:/mnt/nas/documentos ports:
- "8000:8000" networks: - chatbot-network chatbot-frontend:
build: context: ./frontend ports: - "80:80" depends_on:
- chatbot-backend networks: - chatbot-networknetworks:
chatbot-network: driver: bridge4. Archivo de Variables de Entorno
4.1. /mnt/nas/nextcloud-chatbot/.env
Creamos fichero:
nano .envCon el siguiente contenido:
LOCAL_DOCUMENTS_PATH=/mnt/nas/documentos
Construcción y Despliegue de Contenedores
Como estos contenedores Docker tienen muchos componentes unidos en el proyecto, con varias dependencias, es necesario construir en primera instancia las imágenes antes de levantar el contenedor.
Nos colocamos nuevamente en el directorio del proyecto:
cd /mnt/nas/nextcloud-chatbot/Podríamos lanzar el siguiente comando:
docker-compose up --build -dPero os voy a enseñar como hacerlo para cada sección y así poder modificar Backend y Frontend a vuestro antojo. Lo podéis hacer con estos comandos totalmente independientes uno de otro (Frontend para levantarse, necesitará que el Backend esté funcionando sin incidencias):
docker build -f backend/Dockerfile -t chatbot-backend ./backend
docker build -f frontend/Dockerfile -t chatbot-frontend ./frontendCreamos una red para la interconexión de los contenedores:
docker network create chatbot-networkLanzamos la creación de ambos contenedores:
# BACKEND
docker run -v /mnt/nas/documentos/:/mnt/nas/documentos -d --name chatbot-backend --network chatbot-network -p 8000:8000 chatbot-backend
# FRONTEND
docker run -d --name chatbot-frontend --network chatbot-network -p 80:80 chatbot-frontendVerificación despliegue contenedores
Una vez que hemos ejecutado los contenedores de Backend y Frontend, tendremos que revisar los accesos. En mi caso, la máquina virtual Debian tiene la IP 192.168.2.144, así que os explico como accedo al gestor documental desde esa IP.
Para acceder al ChatBot podemos hacerlo de la siguiente forma:
- Frontend: http://192.168.2.144

- API Backend: http://192.168.2.144:8000/docs (documentación interactiva de FastAPI).
Otras validaciones
Si existen problemas en los contenedores, podéis revisar su log para entender el problema:
docker logs chatbot-backenddocker logs chatbot-frontendEs posible también, que tengáis problemas con el Share, y tengáis que revisar si está bien mapeado en vuestro contenedor de Backend:
docker exec -it chatbot-backend ls /mnt/nas/documentosSi queréis revisar el estado de los contenedores usar:
docker ps
Si queréis parar y eliminar los contenedores para recrearlos:
docker stop chatbot-backend chatbot-frontend
docker rm chatbot-backend chatbot-frontend
Tarea Cron para Reindexación Automática
Al estar revisando un Share donde es muy probable que existan cambios, será necesario programar una tarea para que se reflejen en nuestras búsquedas del ChatBot. Para ello programamos en cron una tarea periódica de la siguiente forma:
-
Abre el archivo de tareas cron con:
crontab -e-
Programa la reindexación cada hora:
0 * * * * curl http://localhost:8000/reindex > /dev/null 2>&1Con esto te asegurarás que la información que te devuelve tu ChatBot es fiable.
Conclusión: La transformación digital de tu Empresa
En la era de la transformación digital, la gestión eficiente de documentos es una necesidad esencial para cualquier organización. Un gestor documental no solo centraliza el almacenamiento de archivos, sino que también optimiza los procesos de búsqueda, acceso y colaboración. Herramientas como NextCloud, integradas con sistemas avanzados como este ChatBot de documentos, representan una evolución en la forma en que las empresas y los usuarios manejan su información.
El uso de tecnologías modernas, como el procesamiento de lenguaje natural (NLP) y la inteligencia artificial (IA), permite que los gestores documentales no solo archiven datos, sino que también los comprendan y los hagan accesibles de manera más eficiente. Por ejemplo, un chatbot documental puede interpretar consultas complejas, buscar documentos relevantes e incluso extraer información clave de múltiples formatos, como texto, imágenes o PDF. Esto transforma la experiencia del usuario, reduciendo tiempos de búsqueda y aumentando la productividad.
Además, la incorporación de plataformas colaborativas como NextCloud garantiza que los documentos estén siempre disponibles para todos los usuarios autorizados, desde cualquier lugar, con la seguridad de que los datos están protegidos. Esta integración también facilita la colaboración en equipo y asegura un control de acceso detallado, lo que es fundamental en entornos corporativos.
En conclusión, un gestor documental bien implementado no solo organiza y centraliza la información, sino que también empodera a las organizaciones para tomar decisiones más rápidas y basadas en datos. Ya no se trata solo de almacenar documentos, sino de aprovechar la tecnología para extraer valor de ellos. Así, la gestión documental se convierte en un aliado estratégico para las empresas que buscan ser más ágiles, eficientes y competitivas en el mercado actual. La combinación de IA, seguridad y colaboración marca el futuro de la gestión documental.
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!