



RAG en IA local: Consultar tus documentos sin enviarlos a la nube
Cuando un perfil IT avanza en proyectos de integración IA en su empresa, lo siguiente que suele pedir la dirección o los propios usuarios es poder hacer que el "ChatGPT" conozca nuestros manuales internos, pero de una forma segura.
La pregunta parece sencilla, pero detrás esconde uno de los problemas más comunes que nos encontramos ahora mismo en IT, todo el mundo quiere un asistente que entienda el contexto de su empresa, pero nadie quiere (ni puede, por compliance) subir sus contratos, su código fuente o sus tickets de soporte a un modelo en la nube. Ahí es donde entra RAG, y honestamente, es la pieza que ha hecho que la IA local pase de ser un experimento de fin de semana a algo que se puede defender delante de un director de sistemas.
Si llevas un tiempo trasteando con Ollama, LM Studio o cualquier runtime local, ya sabes que el modelo por sí solo tiene un techo de cristal, solo "sabe" lo que aprendió durante su entrenamiento, que se cortó en una fecha concreta, y no tiene ni idea de qué pone en el PDF de políticas que acabas de subir a tu NAS.
Puedes preguntarle por la capital de Mongolia y te la dirá sin pestañear, pero pregúntale por el procedimiento de rollback de tu última actualización de Proxmox y se inventará algo con total seguridad. Ese es el problema que RAG viene a resolver, y lo hace de una forma bastante más elegante de lo que parece a primera vista.

Qué es RAG (Retrieval Augmented Generation)
RAG significa Retrieval Augmented Generation, o lo que es lo mismo, antes de que el modelo genere una respuesta, vamos a buscar (retrieval) los fragmentos de información relevantes en una base de conocimiento propia, y se los metemos en el contexto junto con la pregunta.
El modelo no "aprende" tu documentación, no la memoriza ni la integra en sus pesos. Simplemente la lee en el momento, como si le pasaras unos folios justo antes de hacerle la pregunta y le dijeras "contesta basándote en esto".
Esto cambia bastante el enfoque respecto a lo que mucha gente imagina cuando piensa en "entrenar una IA con mis datos". El fine-tuning, que es la otra alternativa, implica reentrenar (o ajustar) los parámetros del modelo con tu información, lo cual es caro, lento, y además tiene un problema serio: si tu documentación cambia cada semana (que es lo normal en cualquier empresa viva), tendrías que reentrenar constantemente. Con RAG, en cambio, actualizar el conocimiento es tan sencillo como meter un documento nuevo en la base de datos vectorial. No hay reentrenamiento, no hay GPU quemándose toda la noche, no hay que esperar al fin de semana para lanzar el job.
La arquitectura típica, simplificando bastante, tiene tres piezas:
- Primero, un proceso de ingesta que coge tus documentos (PDFs, wikis, tickets de Jira, lo que sea) y los parte en fragmentos manejables, normalmente de unos pocos cientos de tokens cada uno.
- Segundo, esos fragmentos se convierten en vectores numéricos mediante un modelo de embeddings, y se guardan en una base de datos vectorial: Qdrant, Chroma, Weaviate, pgvector si ya tienes Postgres y no quieres añadir otro servicio más a la pila.
- Y tercero, cuando llega una pregunta, esa pregunta también se convierte en vector, se busca por similitud semántica en la base de datos, y los fragmentos más parecidos se inyectan en el prompt que recibe el modelo. Ese último paso es el que mucha gente subestima, y es donde realmente se nota la diferencia entre una implementación de RAG decente y una que da resultados mediocres.
Ventajas de RAG en IA local frente a modelos en la nube
Aquí viene lo interesante para quien ya está corriendo modelos en su propio hardware. Si tienes un servidor con una GPU decente, yo llevo un tiempo trabajando con una RTX Pro 2000 de 16GB en un Ryzen 9, y va de sobra para esto, montar un pipeline RAG completo es perfectamente viable sin depender de ninguna API externa.
Ollama te sirve el modelo de lenguaje, un modelo de embeddings ligero (nomic-embed-text o similar) se encarga de vectorizar, y Qdrant o Chroma corriendo en un contenedor Docker hacen de almacén vectorial. Todo en tu red, todo bajo tu control, sin que un solo byte de tu documentación interna salga hacia un proveedor externo.
Esto no es un detalle menor para empresas que manejan datos sensibles, contratos con clientes, código propietario o cualquier cosa que entre dentro del paraguas del RGPD. Con un asistente basado en API en la nube, técnicamente estás enviando fragmentos de tus documentos confidenciales a servidores de terceros cada vez que haces una consulta, aunque el proveedor diga que no entrena con tus datos. Con RAG local, ese riesgo simplemente desaparece de la ecuación, y eso es algo que puedes explicarle a un responsable de seguridad sin que se le frunza el ceño.
Ahora, y esto lo digo porque me lo he encontrado de primera mano, no todo es tan bonito como en el diagrama de arquitectura que te enseñan en cualquier charla.
La calidad de un sistema RAG depende muchísimo de cómo trocees los documentos. Si partes el texto en fragmentos demasiado pequeños, pierdes contexto y el modelo recibe trozos inconexos que no le sirven de mucho. Si los haces demasiado grandes, metes ruido y desperdicias la ventana de contexto con información irrelevante que además puede confundir al modelo. Hay técnicas de "chunking" más sofisticadas, como respetar la estructura semántica del documento (separar por secciones, por párrafos completos, por bloques de código si es documentación técnica), que dan resultados notablemente mejores que el típico "corta cada 500 caracteres" que ves en los tutoriales rápidos.
Otro punto que conviene tener en la cabeza, la búsqueda por similitud vectorial no siempre encuentra lo que necesitas, sobre todo si la pregunta usa terminología distinta a la del documento original. Por eso cada vez se ve más la combinación de búsqueda vectorial con búsqueda léxica tradicional (lo que se conoce como búsqueda híbrida), o el uso de un paso de reranking que reordena los resultados candidatos antes de pasárselos al modelo.
Si tu caso de uso es crítico, pongamos, un asistente que da soporte a clientes basándose en tu base de conocimiento, vale la pena invertir tiempo en esa capa intermedia, porque es donde se gana o se pierde la confianza del usuario final.
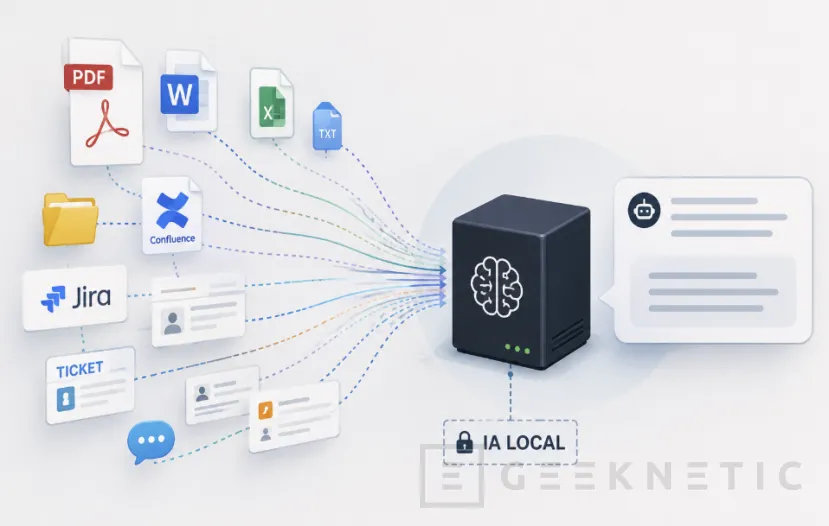
Casos de uso de RAG en Empresas: soporte, runbooks y código interno
En el día a día de IT empresarial, los casos de uso más claros que he visto funcionar bien son los previsibles, pero no por ello menos útiles.
- Un asistente interno que conoce toda la documentación de procedimientos y runbooks, y que responde a preguntas tipo "¿cómo se hace el failover del clúster de Proxmox?" citando el documento exacto de donde sacó la respuesta.
- Un bot de soporte de primer nivel que busca en el histórico de tickets resueltos antes de escalar a una persona.
- Un asistente de código que tiene acceso al repositorio interno y entiende las convenciones específicas de tu empresa, algo que un modelo genérico jamás podría saber por mucho que esté entrenado con medio GitHub.
Lo que sí quiero matizar, porque he visto a más de un equipo lanzarse de cabeza sin pensarlo, es que RAG no es la solución mágica para cualquier problema de "quiero que la IA sepa de mi empresa".
Si tu base de conocimiento es pequeña y cabe perfectamente en la ventana de contexto del modelo (que ahora con modelos de 32k, 128k o más tokens es bastante generosa), a veces simplemente meter el documento entero en el prompt da mejores resultados que montar todo el pipeline de recuperación.
RAG brilla cuando tienes volúmenes grandes de información, cuando esa información cambia con frecuencia, o cuando necesitas trazabilidad de dónde viene cada respuesta. Si no es tu caso, estás añadiendo complejidad de infraestructura que quizá no necesitas.
Cómo montar RAG local con Ollama y Open WebUI en Docker
Para que esto no se quede en la teoría, os cuento la configuración que tengo corriendo a diario, por si os sirve de plantilla.
La base es un Ubuntu Server con una GPU de 16GB de VRAM, 64GB de RAM y 2TB en disco M.2, que es más que suficiente para mover un modelo de lenguaje de tamaño medio y un sistema RAG completo sin que se note el cuello de botella.
Sobre ese servidor tengo Ollama instalado directamente en el host, escuchando en el puerto estándar 11434, y Open WebUI corriendo en Docker, gestionado desde Portainer como un stack independiente.
La pieza que conecta ambos mundos, y que es la que más dudas suele generar a quien empieza, es cómo hace el contenedor de Open WebUI para hablar con Ollama si Ollama no está dentro de Docker.
La respuesta corta es la IP del bridge de Docker, que por defecto suele ser 172.17.0.1. Así queda el docker-compose.yml que tengo desplegado:
services:
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui-stack
ports:
- "8080:8080"
environment:
- OLLAMA_BASE_URL=http://172.17.0.1:11434
- ENABLE_RAG=True
- RAG_EMBEDDING_ENGINE=ollama
- RAG_EMBEDDING_MODEL=nomic-embed-text
- ENABLE_PERSISTENT_CONFIG=True # ¡Cambio clave!
- ENABLE_OCR=True # Activado para PDFs escaneados
- ENABLE_WEB_SEARCH=False
- PDF_EXTRACT_IMAGES=False
volumes:
- open_webui_data:/app/backend/data
extra_hosts:
- "host.docker.internal:host-gateway"
- "jarvis.negu.local:172.17.0.1"
restart: always
network_mode: bridge
volumes:
open_webui_data:
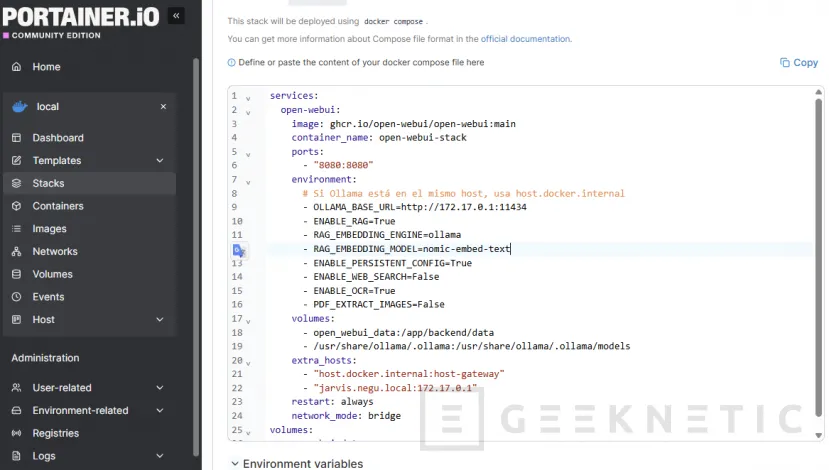
Unas cuantas notas sobre las decisiones que hay detrás de este archivo, porque cada línea responde a un problema concreto que me fui encontrando:
- OLLAMA_BASE_URL apuntando a la IP del bridge en lugar de a localhost es obligatorio en cuanto Ollama vive fuera del contenedor:
- Si lo dejas en localhost, el contenedor busca dentro de sí mismo y no encuentra nada, que es el clásico error de "Ollama no responde" que se ve en los foros.
- RAG_EMBEDDING_ENGINE=ollama es la variable que casi nadie pone y que más quebraderos de cabeza ahorra, le dice a Open WebUI que el motor de embeddings tiene que ser Ollama, en lugar de su motor por defecto basado en SentenceTransformers. Si te la saltas, Open WebUI intenta cargar nomic-embed-text como si fuera un modelo de HuggingFace local, falla en silencio, y la primera vez que subes un documento te explota con un AttributeError: 'NoneType' object has no attribute 'encode' que no dice nada sobre la causa real. Lo digo porque me pasó, y perder media tarde mirando logs de Ollama y de red para descubrir que el problema era una variable de entorno que falta es la clase de error que prefiero ahorrarle a quien lea esto.
- RAG_EMBEDDING_MODEL=nomic-embed-text fija el modelo de embeddings que se usa para vectorizar tanto los documentos como las consultas. Es un modelo ligero, rápido, y con un balance calidad-velocidad que para documentación interna en español funciona razonablemente bien, aunque si tu corpus es muy técnico o muy multilingüe puede que te compense probar alternativas como mxbai-embed-large.
- ENABLE_PERSISTENT_CONFIG=True es la línea que marqué como cambio clave, y no es casualidad, sin ella, cada vez que reinicias el contenedor (por una actualización, por un redeploy desde Portainer, por lo que sea) pierdes los ajustes que hayas tocado desde el panel de administración y vuelves a la configuración de fábrica. Es un fallo silencioso que te puede comer una tarde entera de "¿por qué se ha vuelto a desactivar el RAG si ayer lo dejé funcionando?".
- ENABLE_OCR=True lo activé después de darme cuenta de que buena parte de la documentación que se sube en entornos empresariales son PDFs escaneados o exportaciones de Visio convertidas a imagen, y sin OCR esos documentos entran en la base vectorial vacíos, sin texto que indexar.
- ENABLE_WEB_SEARCH=False es una decisión deliberada de aislamiento, en este servidor no quiero que el asistente salga a buscar en internet bajo ningún concepto, prefiero que se quede limitado a lo que tiene indexado localmente, que es justo el punto de todo este planteamiento.
- El extra_hosts con "jarvis.negu.local" apuntando también al bridge es un capricho de organización interna más que una necesidad técnica, me permite referirme al servidor por nombre desde dentro del contenedor en lugar de memorizar la IP, algo que agradeces cuando tienes media docena de stacks corriendo y cada uno con su propia lógica de red.
- Y el volumen open_webui_data es lo que garantiza que el histórico de conversaciones, los documentos subidos y los embeddings generados sobrevivan a un redeploy del contenedor. Sin volumen persistente, cada actualización de imagen te deja en cero, lo cual en producción es sencillamente inaceptable.
Con esto desplegado, el flujo de trabajo del día a día es bastante directo:
- Subes los documentos desde la interfaz de Open WebUI (o los metes en una colección si quieres organizarlos por departamento o proyecto)
- El sistema los trocea y los vectoriza automáticamente usando el modelo de embeddings configurado
- Y a partir de ahí cualquier conversación que actives con esa colección de documentos hace RAG de forma transparente para el usuario final.
No hay que tocar código, no hay que levantar un Qdrant aparte ni gestionar una base vectorial externa, porque Open WebUI trae su propio almacén vectorial integrado (ChromaDB por defecto) que para volúmenes de documentación departamental va sobrado.
Si en algún momento el volumen de documentos crece a niveles de varios miles de archivos o necesitas búsqueda híbrida más fina, ahí sí que empieza a tener sentido sacar la base vectorial a un servicio dedicado como Qdrant y dejar de depender del almacén embebido, pero para arrancar y para la inmensa mayoría de departamentos de IT de tamaño medio, esta configuración cubre el caso de uso sin complicaciones añadidas.
Un ejemplo concreto: Agregar documentos y Preguntar a la IA
Vale, vamos al caso que más dudas suele generar cuando alguien lo prueba por primera vez, que es el más tonto en apariencia y el más práctico en la realidad, tienes un pendrive o share con un montón de PDFs, manuales, contratos o lo que sea, y quieres que el asistente "se los aprenda" para poder preguntarle cosas sobre ellos.
Aquí conviene aclarar algo desde ya, porque genera bastante confusión, la IA no "aprende" esos documentos en el sentido de que pasen a formar parte de su conocimiento permanente. Lo que pasa es que cada vez que le preguntas algo, el sistema busca los fragmentos relevantes de esos documentos y se los enseña al modelo justo antes de que te responda. Es más parecido a darle un libro abierto en la página correcta que a hacer que se lo memorice.
El proceso, en mi servidor, es así de simple. Conecto el USB al equipo desde el que accedo a Open WebUI (no falta que esté conectado al propio servidor de Ubuntu, basta con tu portátil o tu puesto de trabajo, porque la subida se hace vía navegador). Si quiero hacerlo desde línea de comandos directamente en el servidor, monto el USB y copio los archivos a una carpeta temporal:
# Listar dispositivos para identificar el USB
lsblk
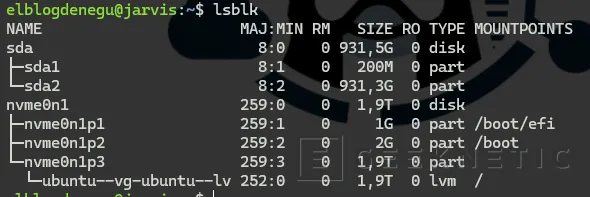
# Montar el USB (suponiendo que aparece como /dev/sda1)
sudo mkdir -p /mnt/usb
sudo mount /dev/sda1 /mnt/usb

# Copiar los documentos a una carpeta de trabajo
mkdir -p ~/docs-ingesta
cp /mnt/usb/*.pdf ~/docs-ingesta/
cp /mnt/usb/*.docx ~/docs-ingesta/ 2>/dev/null
# Desmontar cuando termines, por limpieza
sudo umount /mnt/usb
Subiendo ficheros desde OpenWebUI
Pero, sinceramente, lo normal es ni siquiera pasar por terminal, conectas el USB o la unidad de red al ordenador desde el que abres "http://jarvis.negu.local:8080" (o la IP que toque):
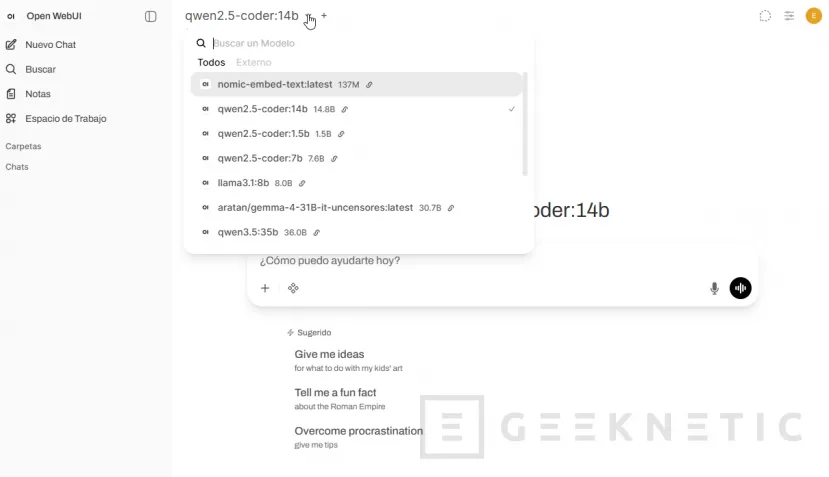
Desde la propia interfaz de Open WebUI vas a Workspace (Espacio de Trabajo) -> Knowledge, creas una colección nueva o nuevo conocimiento:
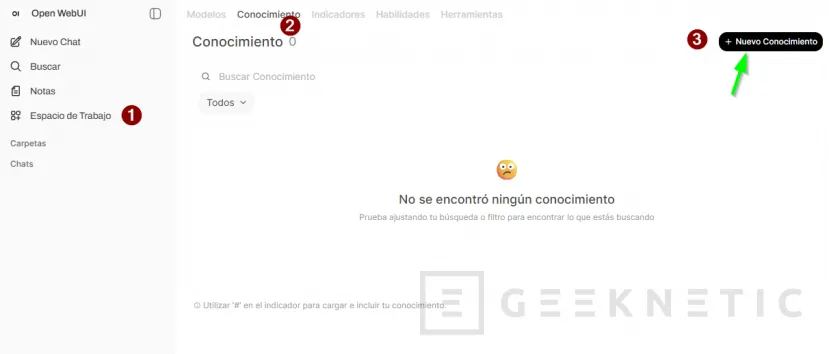
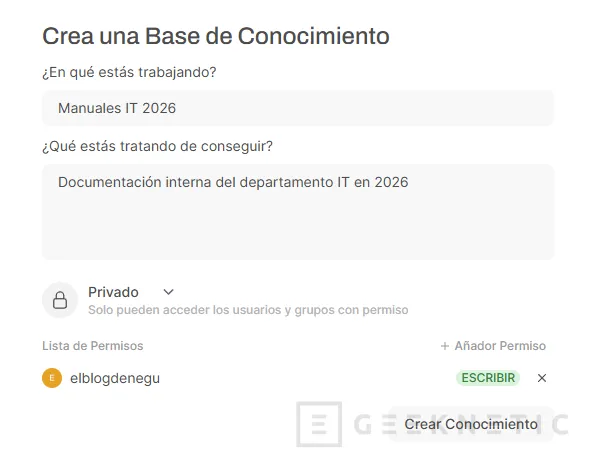
Le das un nombre (por ejemplo "Manuales Proveedor X" o "Contratos 2026"), una descripción, permisos a los usuarios y pulsas crear conocimiento:
Con arrastrar los archivos directamente desde el explorador de archivos del USB hasta el navegador.

Open WebUI los acepta en PDF, Word, texto plano, Markdown, incluso código fuente si lo que quieres indexar es un repositorio.
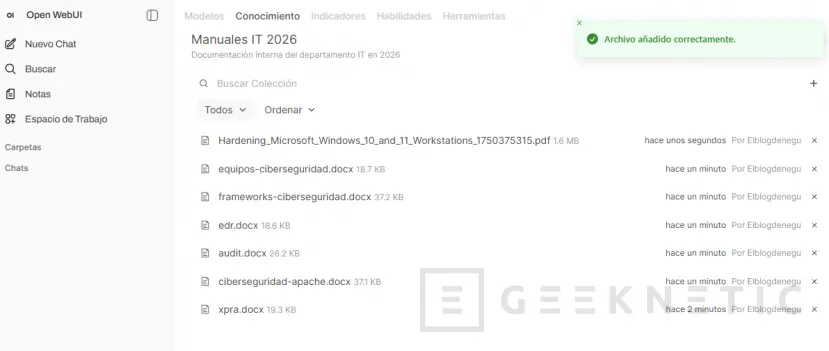
Qué pasa cuando subes los ficheros a tu IA Local
En el momento en que sueltas los archivos, pasan tres cosas en cadena, aunque tú solo veas una barra de progreso.
- Primero, si activaste ENABLE_OCR=True como en mi configuración, cualquier PDF que sea en realidad una imagen escaneada pasa por reconocimiento óptico de caracteres para extraer el texto, si no tuvieras esto activado, esos documentos entrarían vacíos y el asistente nunca podría citarlos.
- Segundo, el texto extraído se trocea en fragmentos (chunks) de un tamaño manejable, normalmente unos cientos de tokens cada uno, intentando no cortar a media frase.
- Tercero, cada fragmento pasa por el modelo de embeddings que configuraste, en mi caso "nomic-embed-text", y se convierte en un vector que se guarda en la base vectorial interna de Open WebUI, asociado siempre al documento y a la colección de origen.
Una vez terminada la ingesta, que para una decena de PDFs de tamaño normal tarda segundos, ya puedes preguntar.
Abres un chat nuevo, seleccionas el modelo que quieras usar (en mi caso suelo tirar de un Llama 3.1 8B o un Qwen2.5 de tamaño medio, que con 16GB de VRAM van fluidos):
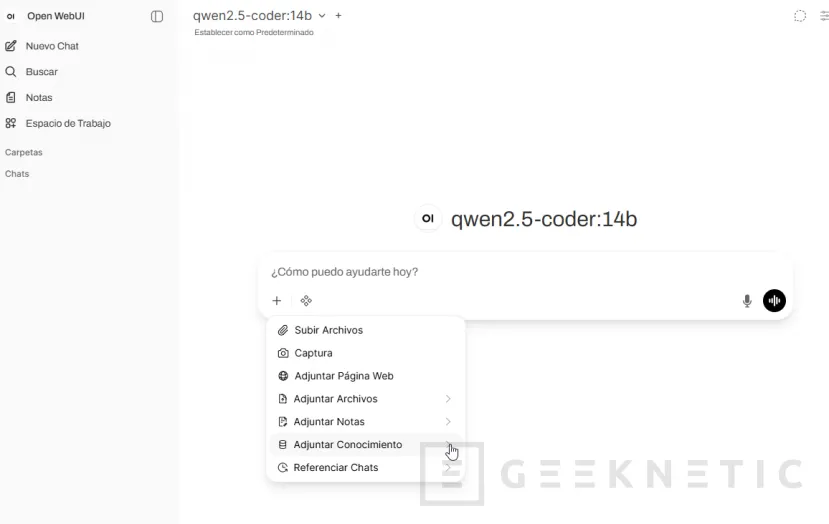
Y antes de escribir la pregunta seleccionas la colección "Manuales Proveedor X" con el icono de adjuntar o escribiendo # seguido del nombre de la colección, según la versión de Open WebUI que tengas.
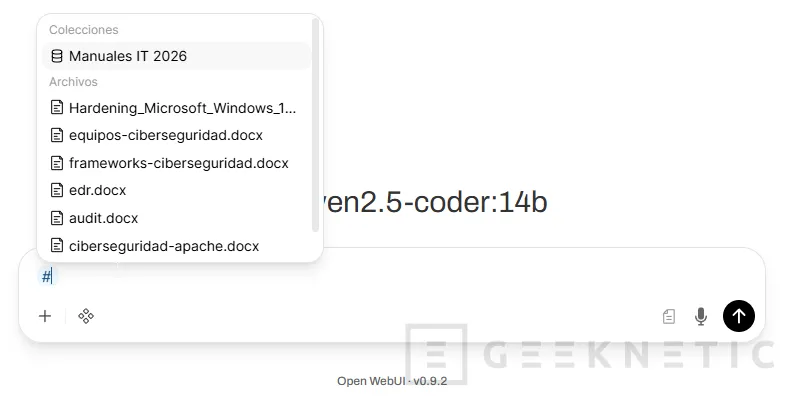
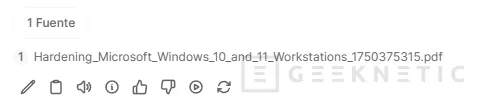
A partir de ahí, cualquier pregunta que hagas en ese chat dispara la búsqueda en esos documentos antes de generar la respuesta. Open WebUI muestra las citas de las fuentes usadas debajo de la respuesta.
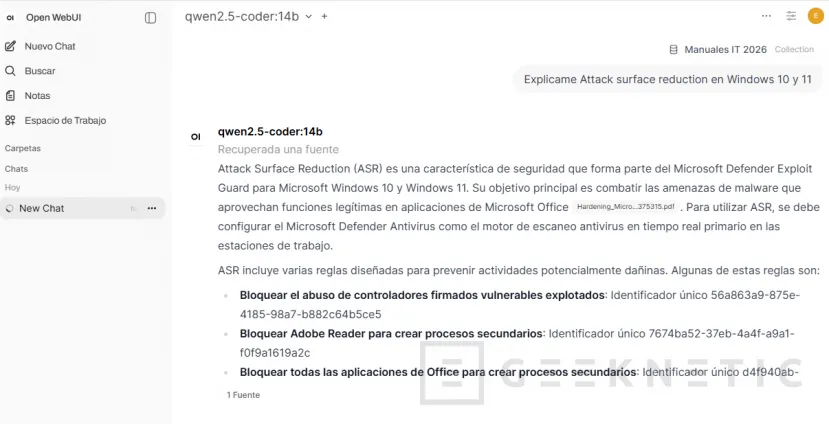
Eso es justo lo que marca la diferencia entre fiarte de una IA a ciegas y poder verificar de un vistazo si la respuesta tiene fundamento real o es una alucinación del modelo.
Una advertencia que merece la pena dejar clara, porque no es evidente a la primera, si subes documentos, contradictorios entre sí a la misma colección, dos versiones de un manual, una desactualizada y otra vigente, por ejemplo, el sistema de recuperación puede traer fragmentos de ambas y el modelo, al no tener criterio propio sobre cuál es la versión correcta, puede mezclar información de las dos sin avisarte.
La solución no es técnica sino de disciplina, mantén las colecciones limpias, retira lo obsoleto en cuanto haya una versión nueva, y si necesitas conservar el histórico, créate una colección separada tipo "Histórico" para no contaminar la que usas en el día a día.
RAG en IA local: conclusiones para departamentos de IT
Después de un tiempo metido en esto, lo que más valoro de RAG combinado con IA local no es solo el ahorro de costes de API, que también lo es, sino la sensación de control que da.
Sabes exactamente qué información tiene acceso tu asistente, puedes auditar qué documentos se están usando para responder, puedes ajustar la base de conocimiento sin depender de nadie, y todo el proceso ocurre dentro de tu propia red. Eso, en un contexto empresarial donde la IA generativa todavía genera bastante desconfianza por motivos legítimos, vale más de lo que parece a primera vista.
No te voy a vender que montar esto es trivial ni que funciona perfecto a la primera. Vas a pelearte con la fragmentación, vas a tener que ajustar cuántos fragmentos recuperar por consulta, y probablemente vas a descubrir que tu primer modelo de embeddings no era el más adecuado para contenido en español o para tu jerga técnica específica.
Pero una vez que el sistema está afinado, la diferencia entre preguntarle algo a un modelo genérico y preguntárselo a uno que conoce de verdad tu organización es abismal. Y esa diferencia, en mi experiencia, es la que convierte la IA local de un juguete interesante en una herramienta que de verdad aporta valor en el día a día de cualquier departamento de sistemas.
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!







