



Análisis Inteligente de Logs con IA Local
Los logs contienen una cantidad enorme de información útil, intentos de acceso fallidos, errores de aplicación, patrones de tráfico anómalos o señales tempranas de un incidente de seguridad.
El problema es que revisar miles de líneas manualmente no es viable. Por eso muchas organizaciones recurren a herramientas de análisis basadas en inteligencia artificial. Sin embargo, gran parte de esas soluciones (ELK, Splunk, Datalog, Sumo Logic...) procesan los datos en infraestructuras externas, lo que plantea dudas razonables sobre privacidad, cumplimiento normativo y protección de información sensible.
La buena noticia es que ya no necesitas enviar tus logs a terceros para obtener análisis inteligentes.
Si dispones de una GPU moderna y tienes Ollama funcionando en tu infraestructura, puedes construir un sistema capaz de analizar logs en tiempo real utilizando modelos de lenguaje ejecutándose completamente en local.
En esta guía vamos a montar un entorno práctico con Docker (para levantar la infraestructura que entregue logs rápidamente), Ollama y Python para crear un analizador de logs privado capaz de clasificar riesgos, detectar comportamientos sospechosos y generar recomendaciones accionables.
¿Qué es un Log?
Antes de empezar, conviene entender el concepto más importante.
Un log es simplemente un registro de algo que ha ocurrido.
Por ejemplo:
2026-06-07 12:30:12 User admin logged inO:
2026-06-07 12:31:08 Failed login for user rootO:
2026-06-07 12:35:44 GET /admin 404Los logs permiten responder preguntas como:
- ¿Quién intentó acceder?
- ¿Qué error ocurrió?
- ¿Cuándo sucedió?
- ¿Con qué frecuencia?
La IA nos ayudará a interpretar grandes cantidades de estos eventos.
Laboratorio Docker de Análisis de Logs
Para poder realizar esta guía, usaremos varios Docker en los que forzaremos logs que puedan generar alertas y validar las configuraciones.
Paso 1: Crear el directorio del laboratorio
Usaré un servidor Ubuntu Server con GPU NVidia de 16GB de VRAM configurada y Ollama instalado.
Crearemos una carpeta para el proyecto:
mkdir ~/soc-labcd ~/soc-labComprueba dónde estás:
pwdDeberías ver algo parecido a:
/home/usuario/soc-lab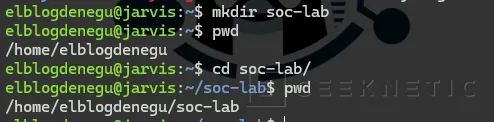
Paso 2: Descargar el modelo de IA
Vamos a utilizar Qwen 14B.
Este modelo ofrece un equilibrio excelente entre calidad y velocidad para análisis de texto.
Descárgalo:
ollama pull qwen2.5:14bLa descarga puede tardar varios minutos.
Cuando termine verifica:
ollama listDeberías obtener algo parecido a:
NAMEqwen2.5:14b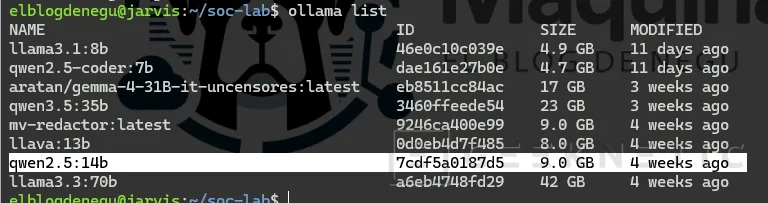
Paso 3: Crear el laboratorio Docker
Dentro de la carpeta del proyecto:
nano docker-compose.yml![]()
Pega exactamente lo siguiente:
services: nginx: image: nginx:latest container_name: soc_nginx ports:
- "8085:80" postgres: image: postgres:16 container_name: soc_postgres
environment: POSTGRES_PASSWORD: laboratorio123 webapp:
image: httpd:latest container_name: soc_webapp ports: - "8081:80"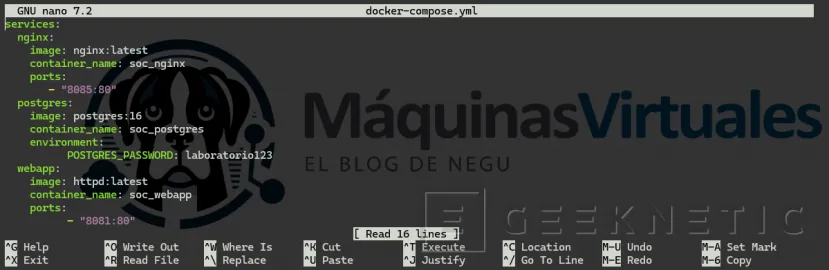
Guardamos el fichero.
Levantar el laboratorio:
docker compose up -d
Comprobar:
docker psDeberías ver tres contenedores activos.
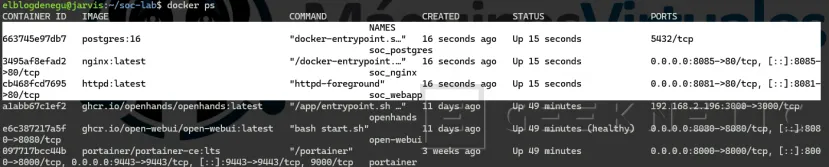
Paso 4: Verificar que los servicios funcionan
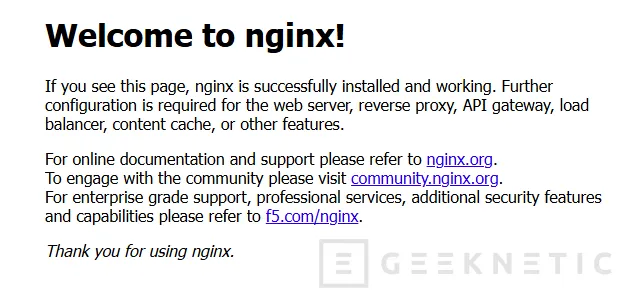
Abrir Nginx:
curl http://localhost:8085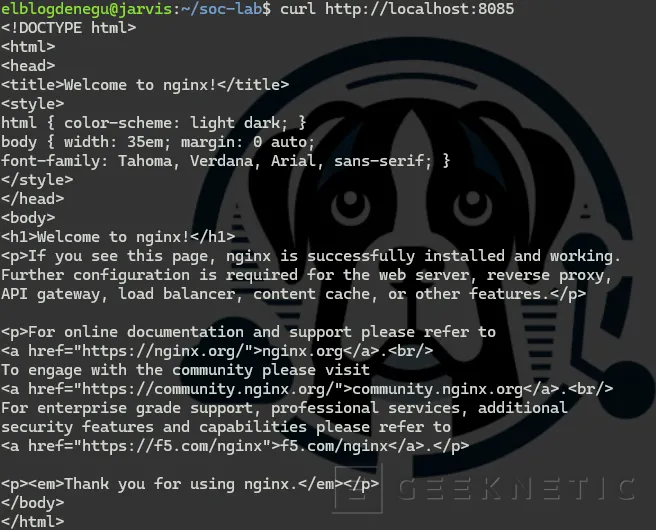
Abrir la aplicación web:
curl http://localhost:8081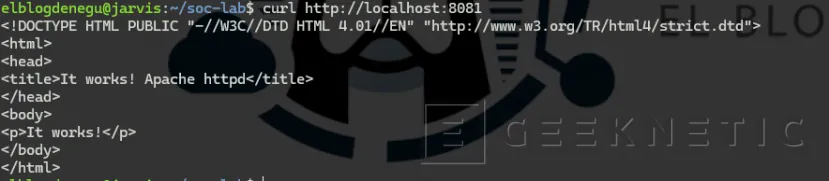
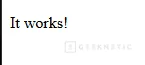
Si aparece HTML, todo funciona correctamente.
Paso 5: Crear el generador de eventos
Ahora necesitamos generar actividad.
Creamos un archivo:
nano generate_logs.py![]()
Contenido completo:
import randomimport timefrom datetime import datetimeeventos = [
"GET /index.html 200", "GET /favicon.ico 404", "GET /admin 403",
"POST /login failed", "POST /login success",
"Database connection timeout", "Invalid credentials",
"User admin logged in", "User test failed authentication",
"Multiple requests from same IP"]while True:
evento = random.choice(eventos) with open("soc_events.log", "a") as f:
f.write( f"{datetime.now()} - {evento}\n" )
print(evento) time.sleep(2)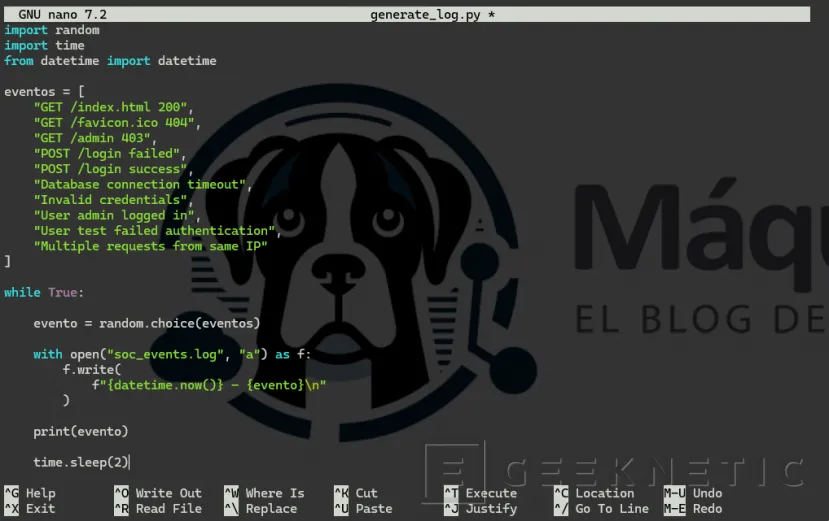
Guardamos el fichero.
Paso 6: Ejecutar el generador
Instalar Python si fuera necesario:
sudo apt install python3 -yEjecutar:
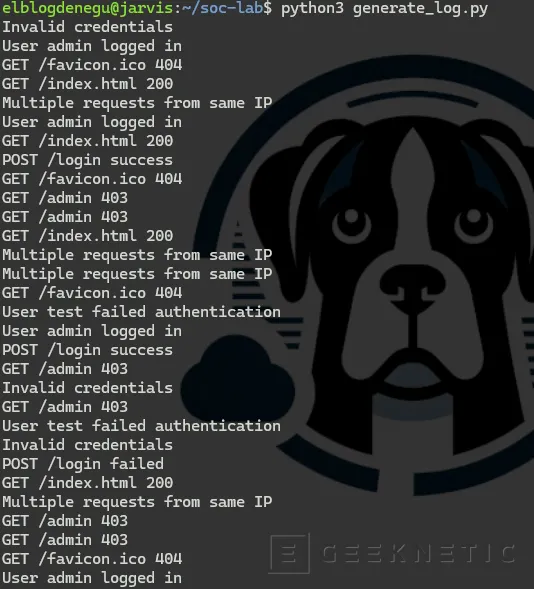
python3 generate_logs.pyVerás eventos apareciendo constantemente.
Deja esta terminal abierta.
Abre otra sesión SSH para continuar.
Paso 7: Ver los logs generados
En la nueva terminal:
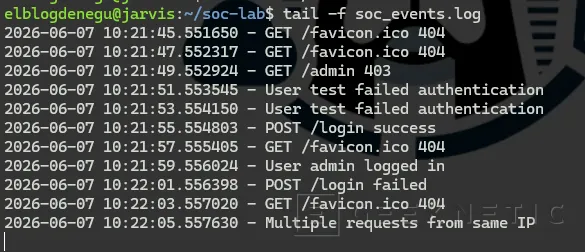
tail -f soc_events.log
Aparecerán entradas similares a:
2026-06-07 20:15:33 - GET /admin 4032026-06-07 20:15:35 - User admin logged in
2026-06-07 20:15:37 - Invalid credentialsYa tenemos datos para analizar.
Paso 8: Crear el analizador con IA
Crear archivo:
nano soc_analyzer.pyPegar:
import requestsOLLAMA_URL = "http://localhost:11434/api/generate"
MODEL = "qwen2.5:14b"PROMPT = """Eres un analista SOC Tier 1.
Analiza estos eventos.Identifica:- Errores repetitivos
- Posibles intentos de acceso no autorizado- Problemas de autenticación
- Actividad sospechosaClasifica el riesgo:BAJOMEDIOALTOCRITICOResponde con:
RIESGO:HALLAZGOS:ACCION:"""with open("soc_events.log") as f: logs = f.read()
payload = { "model": MODEL, "prompt": PROMPT + "\n\n" + logs,
"stream": False}response = requests.post( OLLAMA_URL, json=payload)
print( response.json()["response"])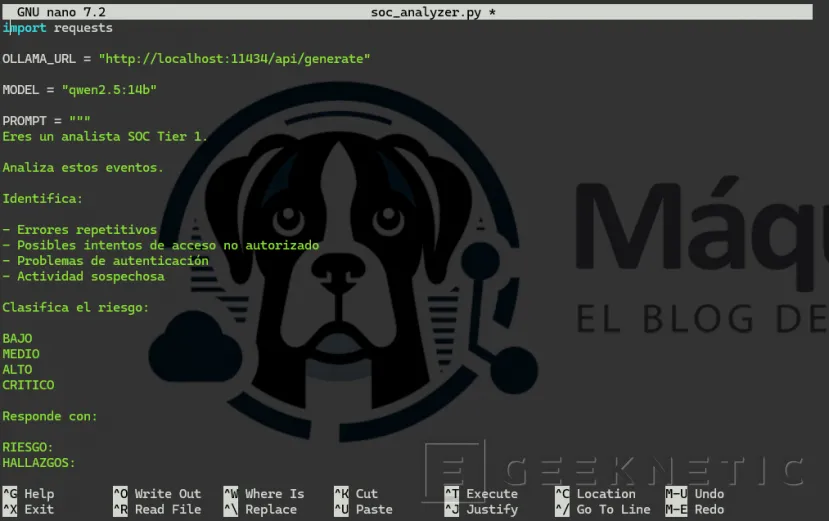
Guardar.
Si tenéis capacidad podéis mejorar el análisis de logs modificando:
logs = f.read()
Por:
logs = "".join(
open("soc_events.log").readlines()[-500:]
)
Así el modelo analizará los últimos 500 eventos.
Paso 9: Instalar dependencias
elblogdenegu@jarvis:~$ cd soc-lab/
elblogdenegu@jarvis:~/soc-lab$ python3 -m venv venv
elblogdenegu@jarvis:~/soc-lab$ source venv/bin/activate
(venv) elblogdenegu@jarvis:~/soc-lab$ pip install requests
Paso 10: Ejecutar el análisis
Con tres ventanas a la vez corriendo, una que genera los logs, otra que los recoge a un fichero y por último lanzamos desde otra consola:
python3 soc_analyzer.py![]()
Tras unos segundos (según la potencia de tu GPU) recibirás una respuesta similar a:
RIESGO: MEDIOHALLAZGOS:1. Múltiples errores de autenticación.
2. Accesos repetidos a rutas restringidas.3. Varias respuestas HTTP 403.ACCION:
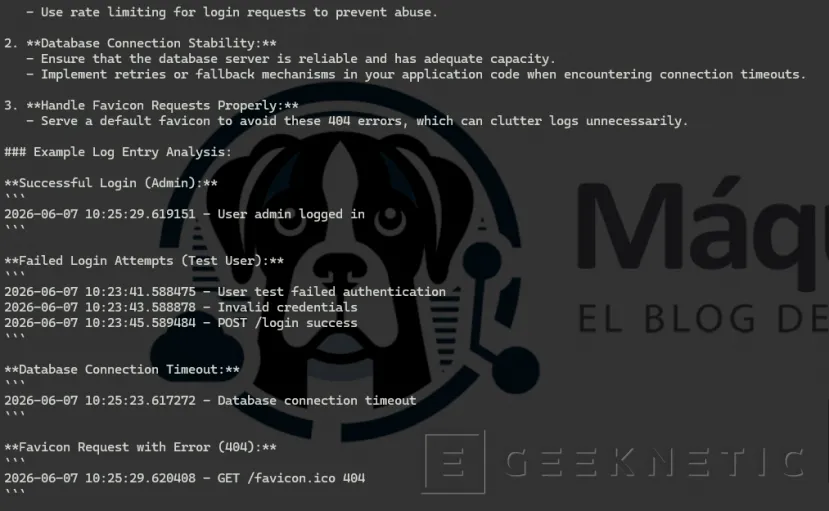
- Revisar origen de accesos.- Monitorizar intentos fallidos.
- Verificar usuarios activos.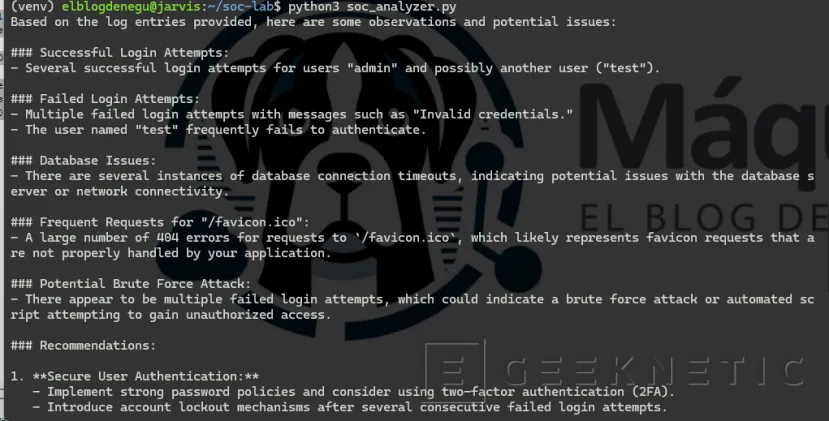

Si has mejorado el contexto, para que analice muchos más logs, el resultado será mejor:
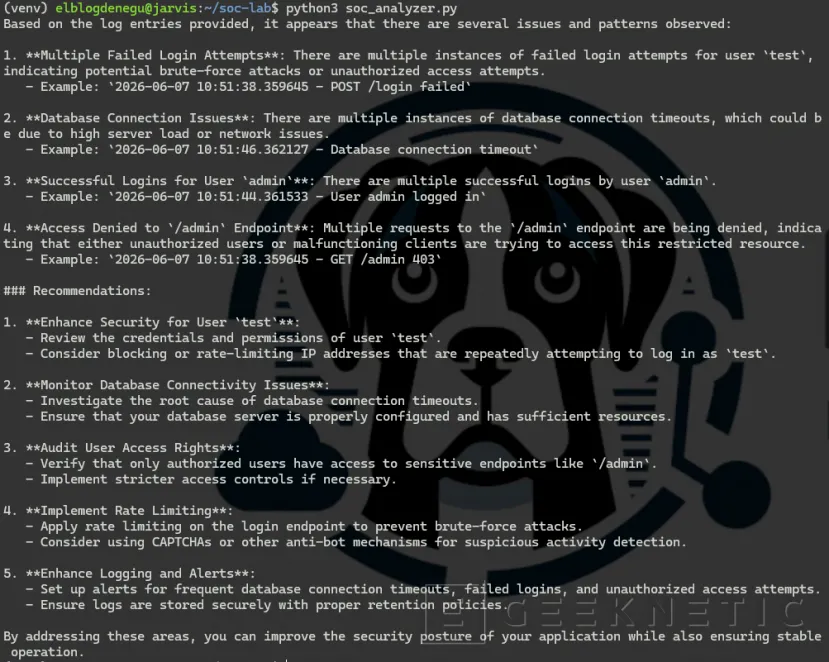
Ya tienes un SOC básico funcionando con Ollama y GPU local. Sin tener que mandar tus datos a la nube.
Paso 11: Próximos pasos
Puedes programar análisis periódicos.
Editar cron:
crontab -eAñadir:
*/15 * * * * /usr/bin/python3 /home/usuario/soc-lab/soc_analyzer.py >> /home/usuario/soc-lab/report.logCada 15 minutos se generará un nuevo informe.
Una vez tengas la validación y todo funcionando puedes ampliarlo con:
- Alertas Telegram
- Alertas Discord
- CrowdSec
- Fail2Ban
- Grafana
- Loki
- Wazuh
- RAG sobre históricos de logs
Cada una de esas mejoras convierte el laboratorio en un entorno más cercano a un SOC real.
IA Local como herramienta del SOC
La IA local aporta algo especialmente valioso en entornos de operaciones y seguridad, contexto.
Mientras las herramientas tradicionales muestran miles de líneas de texto, un modelo local puede resumir eventos, identificar patrones y priorizar aquello que realmente requiere atención. Es la diferencia entre leer un diccionario y que alguien te explique lo relevante.
No sustituye, por ejemplo, a un SOC ni a una plataforma SIEM, pero sí puede actuar como una capa inteligente de análisis que reduzca significativamente el tiempo dedicado a revisar logs (el humano, al menos por ahora, siempre tiene que validar lo que se analiza). Piénsalo como un analista junior que trabaja 24 horas, no se cansa y nunca pide vacaciones, pero que necesita supervisión antes de tomar decisiones.
Y lo mejor es que todo ocurre dentro de tu propia infraestructura.
- Sin APIs externas.
- Sin costes por uso.
- Sin que los datos abandonen tu red.
En seguridad, controlar dónde van tus datos no es un detalle técnico, es una decisión estratégica. Y ahora mismo el tiempo ante un problema, es crítico, en cualquier infraestructura de una media o gran empresa.
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!







