



AMD lanza ROCm 7.0 con integración para Instinct MI350, comunicaciones GPU-GPU y AI Workbench
por Manuel NaranjoAMD ha movido ficha con ROCm 7.0, y no es la de una actualización menor. Es un paquete que alinea silicio, formatos numéricos y herramientas de despliegue para que sus GPUs compitan de verdad en entrenamiento e inferencia, desde un nodo único hasta clústeres multirack.
La pieza de hardware que vertebra el anuncio es la nueva familia Instinct MI350 (CDNA 4), con HBM más aprovechada y soporte nativo a precisiones que hasta hace poco eran experimentales. Pero el mensaje va más allá del data center: AMD quiere que el mismo stack corra también en Ryzen AI y Radeon RX, de modo que el flujo “del portátil al rack” sea coherente.
CDNA 4 y HBM: el cimiento técnico del cambio
El bloque de cómputo cambia cuando el software sabe exprimirlo. ROCm 7.0 introduce kernels y rutas de datos que intercalan HBM, caches y operadores de forma más eficiente, algo clave cuando un modelo grande no cabe completo en memoria y hay que paginar con criterio. CDNA 4, por su parte, aporta ancho de banda y soporte ampliado de tipos, de forma que ya no dependes del viejo FP16/INT8 como únicas palancas para recortar costes. Esa combinación es la que permite a AMD hablar de “avance generacional” sin esconderse.
El punto más rompedor es el soporte estable para FP4, FP6 y FP8. No se trata de “bajar bits” sin más: ROCm 7.0 acompaña estos formatos con escalados y calibraciones que evitan degradaciones abruptas en convergencia o calidad de salida. En entrenamiento, FP8 bien orquestado reduce memoria y tráfico entre GPUs; en inferencia, FP4/FP6 disparan el throughput cuando hay que servir millones de tokens al día. El resultado práctico es simple: más modelos por tarjeta y más consultas por vatio.
La librería llega con razonamiento optimizado y con soporte de Mixture of Experts disperso listo para producción. Esto incide en el coste por token y latencia p95. Si a la atención más ligera sumas MoE que activa solo los expertos necesarios, el costo marginal cae de forma visible. AMD asegura mejoras claras frente a ROCm 6.0 en tareas de modelos grandes; como siempre, las cifras de proveedor requieren validación externa, pero el enfoque técnico es el correcto.
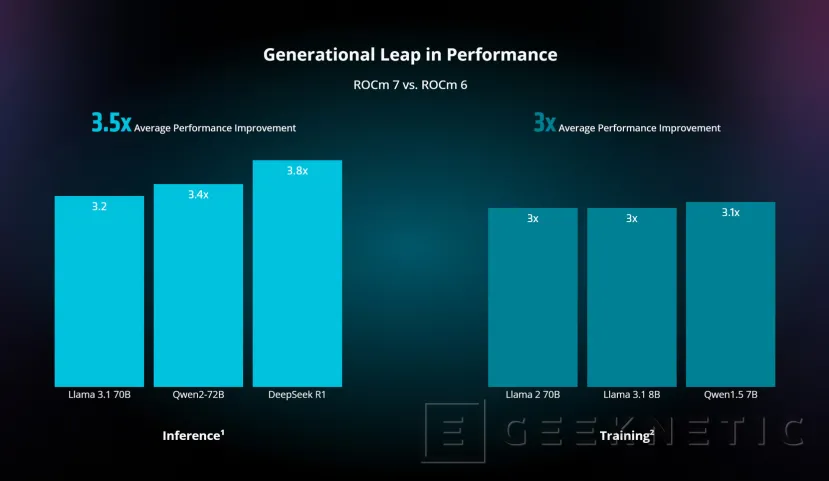
Escalado entre nodos: menos cola, más rendimiento
ROCm 7.0 habilita comunicación directa GPU-GPU e inferencia distribuida con compatibilidad para vLLM-d y DeepEP. Traducido: menos saltos por CPU, menos sobrecarga en el stack de comunicaciones y más uso efectivo de cada acelerador cuando paralelizas por tensor o por pipeline. En despliegues reales, ese recorte de cola y sincronizaciones se nota más que un buen micro-kernel aislado.
Operaciones y observabilidad: del prototipo al “siempre en verde”
La teoría no sirve sin panel de control. Dos piezas nuevas apuntalan el tramo de operaciones: AMD Resource Manager, para particionar, programar y aislar cargas en clústeres heterogéneos, y AI Workbench, pensado para orquestar y monitorizar entrenamientos e inferencias con métricas que importan (uso de HBM, caudal de tokens, contención en redes). Son las herramientas que reducen la distancia entre el cuaderno de pruebas y el SLA.
Contenedores listos y stacks abiertos: tiempo ganado
El equipo que llega con prisa no quiere compilar medio ecosistema. Por eso, AMD publica imágenes Docker preconstruidas con modelos cuantizados de ejemplo y stacks listos para los frameworks habituales. El valor no es solo pedagógico: acelera POCs y evita semanas de ajustes menores. Además, la integración con pilas de servidor de código abierto reduce el riesgo de “islas” en producción.
Abrir ROCm 7.0 a Ryzen AI y Radeon RX significa que puedes probar en local una versión comprimida del pipeline y escalar sin cambiar de herramienta. Para un equipo pequeño, esto evita bifurcaciones de código y facilita reproducir errores. Para una empresa grande, reduce fricción entre los entornos de desarrollo, staging y producción.
Qué mirar con lupa a partir de hoy
El movimiento es ambicioso y bien orientado, pero hay tres variables que determinarán su impacto real: madurez de kernels (especialmente en operadores frontera como atención con KV-cache larga), estabilidad de las rutas de comunicación bajo presión continua y calidad de la documentación para equipos que migran desde CUDA. Con ROCm 7.0 AMD ha puesto los cimientos y la escalera; la adopción dependerá de que subir los peldaños sea tan directo como prometen sus contenedores y sus nuevas herramientas.
En conjunto, ROCm 7.0 no es una promesa vacía ni una simple lista de parches. Es un paquete coherente (CDNA 4 + precisiones modernas + distribución entre nodos + tooling de clúster) que ataca las dos métricas que mandan en IA: coste por token y utilización sostenida del acelerador. Si la comunidad confirma los números y los equipos de plataforma encuentran menos piedras en el camino, AMD habrá pasado de alternativa teórica a opción operativa con la que planificar el próximo año.
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!







