



El AMD Ryzen AI MAX+ 395 de 128 GB es capaz de ejecutar en local lenguajes de hasta 128.000 millones de parámetros
por Juan Antonio Soto 1AMD ha apostado esta generación por una APU más potente para sus dispositivos portátiles, los AMD Ryzen AI MAX+, que cuentan con una NPU dedicada XDNA 2 para tareas de inteligencia artificial. Además de esta NPU y una CPU con hasta 16 núcleos Zen 5, los modelos más potentes se caracterizan por ofrecer una GPU integrada Radeon 8060s con hasta 40 CUs RDNA 3.5. Una GPU que además de ser ideal para juegos también se defiende bien con la IA.
Ejecuta en local lenguajes de hasta 128.000 millones de parámetros
Pero AMD acaba de realizar una actualización para estos procesadores que, con la última versión de sus drivers AMD Software Adrenaline Edition 25.8.1, se ha introducido un nuevo controlador que permitirá ejecutar modelos de hasta 128 mil millones de parámetros de forma local en el más potente de estos AMD Strix Halo, el Ryzen AI MAX+ 395 junto con 128 GB de RAM. Esto ofrece compatibilidad con lenguajes grandes como Llama 4 Scout 109B de Meta, con soporte para Vision y MCP (Model Context Protocol) a través de llama.cpp + Vulkan.
El AMD Ryzen AI MAX+ 395 es el primer PC en ejecutar Llama 4 Scout 109B con Vision y MCP de forma local

Esto convierte a esta APU potente de AMD en el primer procesador de consumo capaz de ejecutar modelos tan grandes de forma local. Además de este, esta APU ya soportaba otros modelos como DeepSeek R1 Distill Llama 70B o Llama 3.3 70B, que seguirán estando disponibles además de introducir estos más grandes.
La función VGM asigna 96 GB de memoria dedicados para la GPU
Para esto se ha empleado una mejora en la función VGM (Variable Graphics Memory) capaz de asignar hasta 96 GB de memoria a la GPU integrada Radeon 8060s, que puede con estos lenguajes de hasta 128B en 4 bits o 32B en FP16.
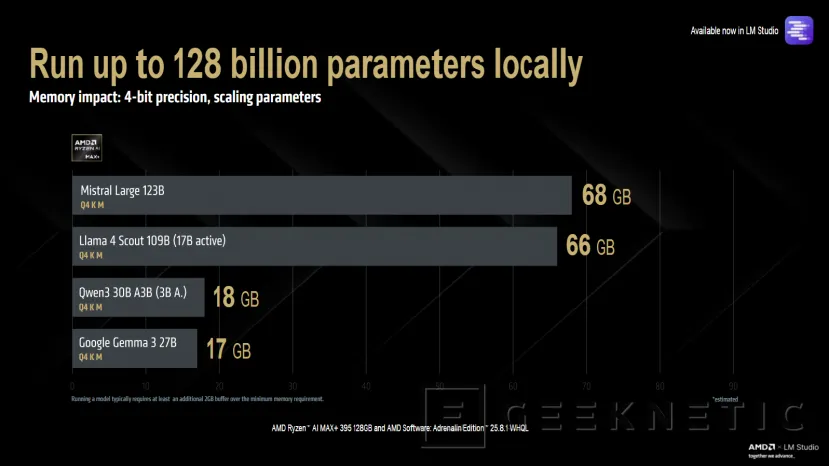
AMD también ha especificado el impacto de memoria que genera cada lenguaje, incluido este de mayor tamaño que ahora es capaz de ejecutar. Con una precisión de 4 bits, para Mistral Large de 123B se necesitan 68 GB, para Llama 4 Scout 109B bastan con 66 GB, mientras que otros lenguajes como Qwen3 30B A3B o Google Gemma 3 27B solo necesitan entre 18 y 17 GB. También puedes incrementar la precisión, ya que con 60 GB de VRAM puedes ejecutar Qwen3 30B A3B con precisión FP16, rebajándose casi a la mitad de VRAM necesaria con precisión Q8.
Con mayor longitud de contexto aumenta la memoria operativa, conversaciones más largas y procesamiento de documentos más extensos
Con esta nueva capacidad de memoria de 96 GB dedicados para la GPU, también se ofrecen nuevas funciones con Agentes de Inteligencia Artificial. Esto permite longitudes de contexto mayores que las habitualmente empleadas, permitiendo más información para procesar con una sola entrada y permitiendo mayor memoria operativa. Además, también permitirá a los lenguajes ofrecer conversaciones más largas sin perder el hilo y procesar documentos más extensos sin tener que partirlos en varias partes.

Por defecto LM Studio ofrece una longitud de 4.096 tokens, pero se pueden ofrecer hasta 32.000 con Google Gemma 3n E4b o incluso llegar a los 200.000 tokens con varias entradas. Esto es posible con este procesador de AMD y la última versión de los drivers, expandiendo sus posibilidades en la implementación de nuevas funciones con MCP.
Descarga ya la última versión de los drivers AMD Software Adrenaline Edition 25.8.1
Ya puedes descargar esta nueva versión de los drivers que ofrece esta nueva capacidad con este todopoderoso AMD Ryzen AI MAX+ 395.
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!







