



Configura tu asistente de código local en VS Code con Ollama
Las herramientas de asistencia al desarrollo basadas en inteligencia artificial se han convertido en parte habitual del flujo de trabajo de muchos programadores.
Soluciones como GitHub Copilot o Cursor ofrecen autocompletado inteligente, chat contextual y generación de código prácticamente instantánea. El problema es que, para proporcionar esas capacidades, tu código suele procesarse en infraestructuras de terceros.
Para proyectos personales esto puede no ser un inconveniente. Para entornos empresariales, código propietario o desarrollos sujetos a acuerdos de confidencialidad, la situación cambia por completo.
La buena noticia es que hoy es posible construir una alternativa local sorprendentemente potente utilizando modelos open source, una GPU moderna y herramientas gratuitas.
En esta guía configuraremos un asistente de programación privado basado en Ollama, Continue y Qwen2.5-Coder capaz de ofrecer:
- Autocompletado inteligente en tiempo real
- Chat contextual dentro de VS Code
- Refactorización asistida por IA (mejora de código sin tocar funcionalidad mediante IA)
- Comprensión del repositorio completo
- Procesamiento 100% local
Sin suscripciones mensuales.
Sin dependencias de proveedores externos.
Y sin que tu código abandone tu infraestructura.
GitHub Copilot vs Solución Local
Antes de empezar conviene entender qué estamos construyendo:
|
Característica |
GitHub Copilot |
Stack Local |
|---|---|---|
|
Coste mensual |
Sí |
No |
|
Código sale de tu red |
Sí |
No |
|
Funciona sin Internet |
No |
Sí |
|
Control del modelo |
Limitado |
Total |
|
Modelos personalizables |
Parcial |
Completo |
|
Instalación inicial |
Muy simple |
Media |
No se trata de replicar exactamente todas las funcionalidades de Copilot Enterprise.
El objetivo es cubrir la mayoría de casos de uso diarios de un desarrollador manteniendo el control absoluto sobre los datos.
Montar un servidor local no implica que sea todo "gratis", tiene un coste altísimo de compra tal y como están los componentes hoy en día y otros gastos implícitos de tener el servidor encendido y depender de él para realizar ciertas tareas. A cambio, dispones del control total (con lo que ello implica también).
Arquitectura y Requisitos de la solución
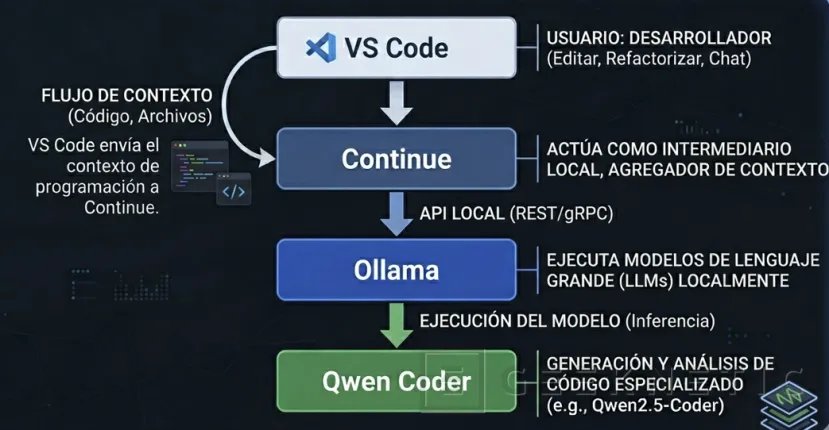
La arquitectura es sencilla:
- VS Code envía el contexto de programación a Continue.
- Continue actúa como intermediario y se comunica con Ollama.
- Ollama ejecuta localmente los modelos especializados en generación y análisis de código.
Requisitos previos
Necesitarás:
- VS Code instalado
- Un servidor o equipo con Ollama funcionando
- Una GPU moderna (recomendable)
- Acceso de red entre VS Code y el servidor
- Mínimo entre 10 y 15 GB de almacenamiento libre
No es necesario crear cuentas ni registrarse en ningún servicio.
Instalación de Modelos de Ollama y Extensión Continue en Visual Code
Para este ejemplo, usaremos un servidor Ubuntu Server + Ollama + GPU PNY RTX 2000 PRO 16GB Blackwell y una máquina para desarrollar con Windows 11 + Visual Code instalado:
Paso 1: Descargar los modelos
Para obtener una experiencia fluida utilizaremos dos modelos diferentes.
- Uno para chat y análisis profundo:
ollama pull qwen2.5-coder:7b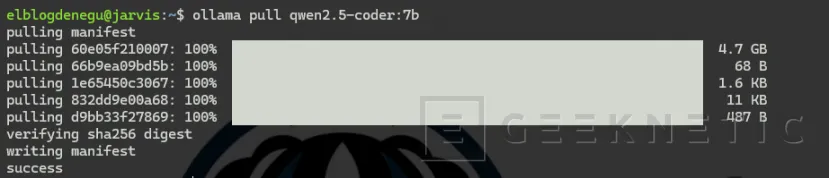
- Y otro optimizado para autocompletado rápido:
ollama pull qwen2.5-coder:1.5b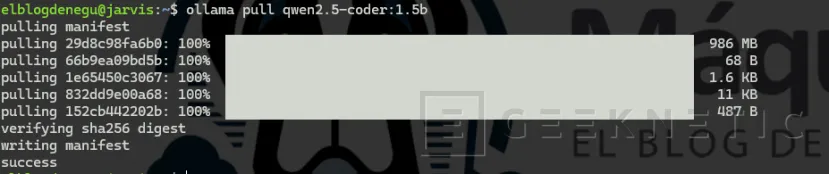
Esta separación tiene una ventaja importante.
- El autocompletado se ejecuta constantemente mientras escribes, por lo que necesita tiempos de respuesta extremadamente bajos.
- Las tareas de chat, refactorización o explicación de código toleran algo más de latencia y se benefician de modelos más grandes.
Si dispones de 12 GB o más de VRAM, considera utilizar:
ollama pull qwen2.5-coder:14b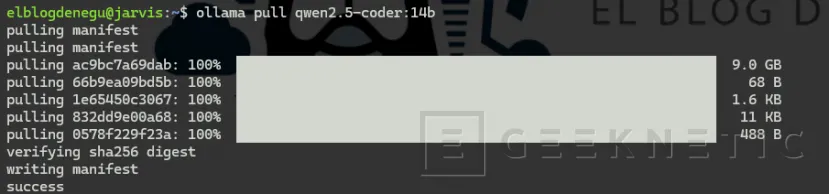
Comprueba que los modelos están disponibles:
ollama list
Paso 2: Permitir conexiones desde la red local
Por defecto, Ollama escucha únicamente en localhost.
Si VS Code está instalado en otra máquina, debes exponer el servicio.
Edita la configuración:
sudo systemctl edit ollamaAñade:
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"

Aplica los cambios:
sudo systemctl daemon-reloadsudo systemctl restart ollamaVerifica desde la máquina Windows que puedes acceder:
curl http://IP_SERVIDOR:11434/api/tags
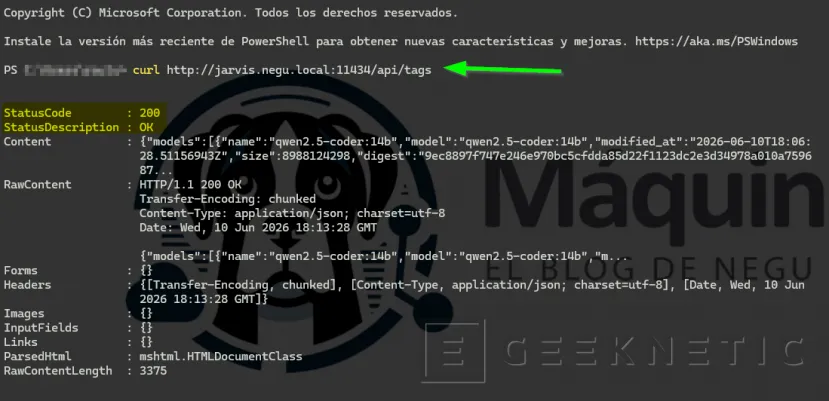
Si no responde, revisa las reglas de firewall.
Paso 3: Instalar Continue
Continue es una de las extensiones más maduras para conectar modelos locales con VS Code.
Instalación:
- Abrir Extensions (Ctrl + Shift + X)
- Buscar "Continue"
- Instalar la extensión
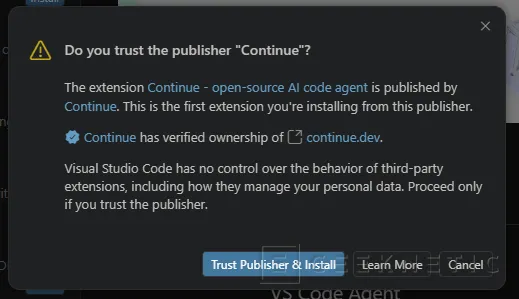
Pulsamos "Trust Publisher & Install":
- Reiniciar VS Code. Al abrir nuevamente verás un icono nuevo en el lateral:
Configurar Extensión Continue para IA Local
Continue, como hemos dicho, es la extensión que hace de puente entre VS Code y tu Ollama. Es open source, activa, y tiene mejor integración con modelos locales que cualquier alternativa que haya probado.
Una vez instalada la extensión, verás el icono de Continue en la barra lateral.
Seguiremos los siguientes pasos para la configuración:
- En VS Code, pulsa en el sobre el icono de la extensión:

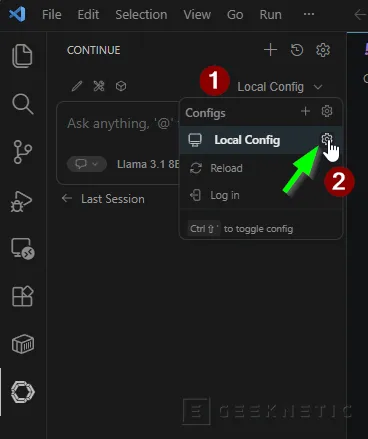
- Despliega Local Config. Haz clic en el icono del engranaje "Local Config":
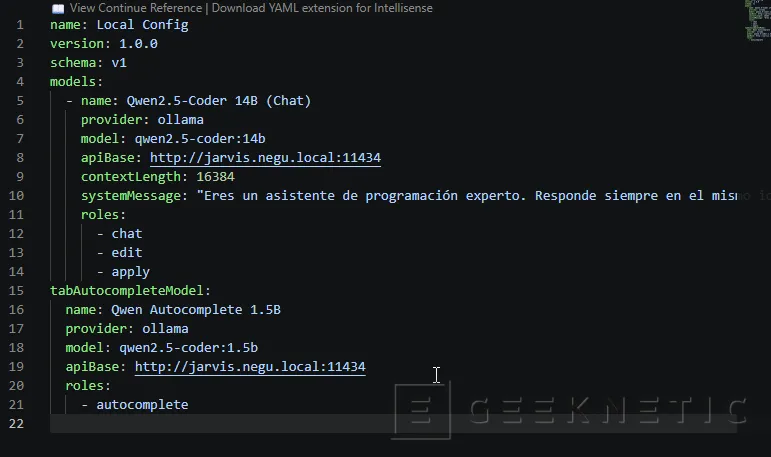
- Vamos a editar el fichero original config.yaml:
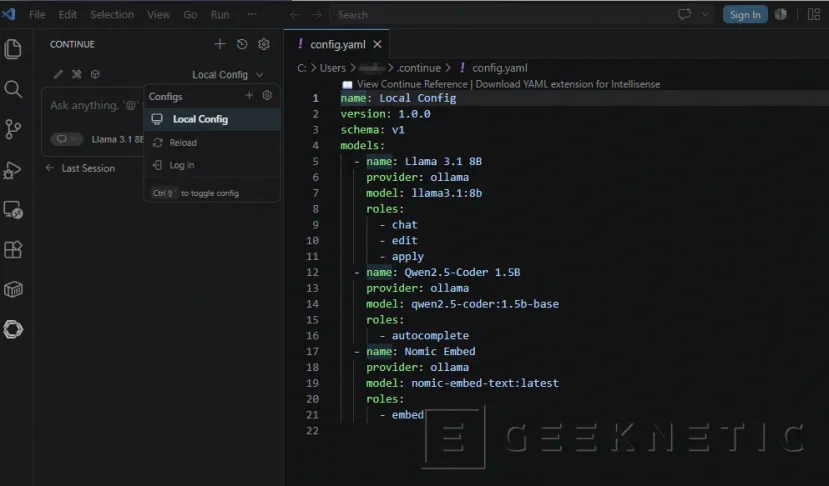
- Por este contenido, cambiando el nombre / IP del servidor:
name: Local Config
version: 1.0.0
schema: v1
models:
- name: Qwen2.5-Coder 14B (Chat)
provider: ollama
model: qwen2.5-coder:14b
apiBase: http://IP-SERVIDOR:11434
contextLength: 16384
systemMessage: "Eres un asistente de programación experto. Responde siempre en el mismo idioma en que te hagan la pregunta. Cuando generes código, incluye únicamente el código sin explicaciones adicionales a menos que te las pidan explícitamente."
roles:
- chat
- edit
- apply
tabAutocompleteModel:
name: Qwen Autocomplete 1.5B
provider: ollama
model: qwen2.5-coder:1.5b
apiBase: http://IP-SERVIDOR:11434
roles:
- autocomplete
- Guardamos el fichero. Automáticamente dispondremos del modelo:
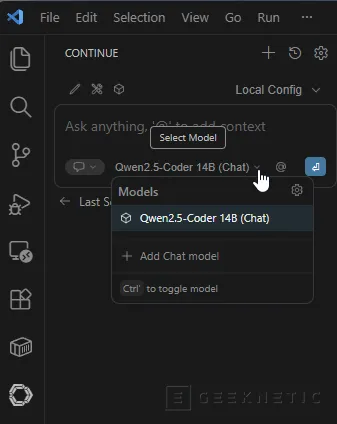
Primeras pruebas IA Local + VS Code
Para comprobar que todo el sistema (Chat + Autocompletado) funciona a la perfección, vamos a hacer una prueba real en VS Code.
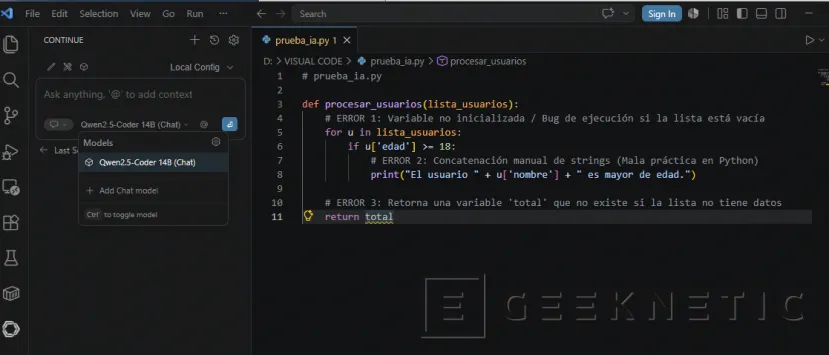
Os dejo un script de Python que contiene malas prácticas, un bug y falta de tipado. Guarda este código en un archivo llamado prueba_ia.py:
# prueba_ia.py
def procesar_usuarios(lista_usuarios):
# ERROR 1: Variable no inicializada / Bug de ejecución si la lista está vacía
for u in lista_usuarios:
if u['edad'] >= 18:
# ERROR 2: Concatenación manual de strings (Mala práctica en Python)
print("El usuario " + u['nombre'] + " es mayor de edad.")
# ERROR 3: Retorna una variable 'total' que no existe si la lista no tiene datos
return total
Prueba 1: Comprobar el Chat
Vamos a probar el modelo grande (Qwen2.5-Coder 14B) para que analice y refactorice el código.
- En VS Code, abre el archivo prueba_ia.py
- Selecciona todo el código con Ctrl + A.
- Pulsa Ctrl + L. Verás que el código seleccionado se adjunta automáticamente al chat de Continue en la barra lateral.
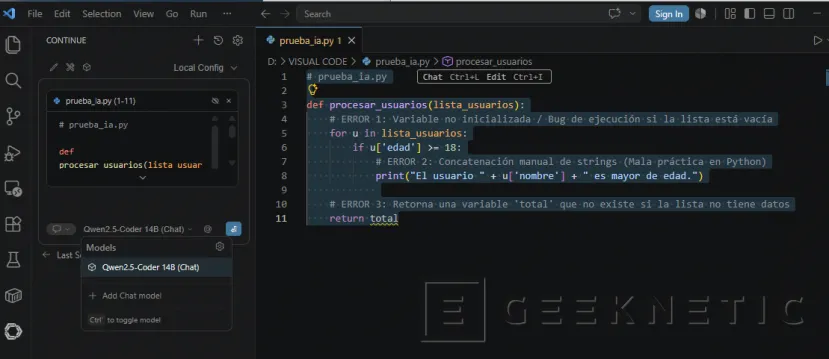
- Escribe en el chat: "¿Qué errores ves en este código y cómo lo mejorarías?"
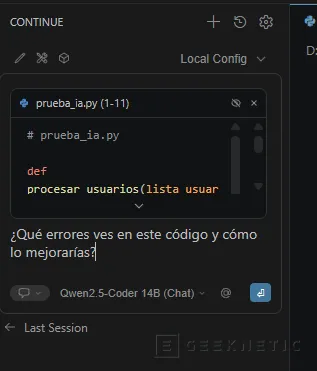
- Pulsa Enter.
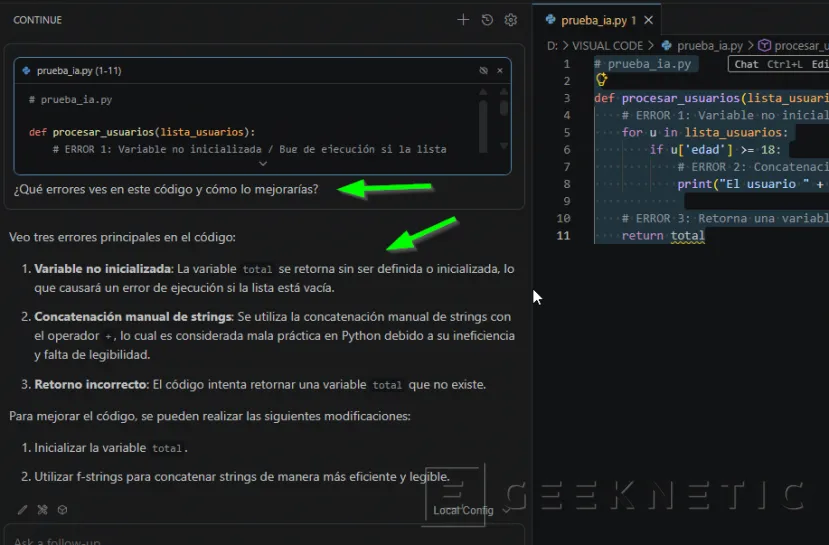
- Qwen, si funciona bien, detectará los tres fallos principales y te devolverá una respuesta directa (cumpliendo tu directiva de no dar rodeos) con el código corregido:
Solución al Bug: Inicializará el contador total al principio de la función.
Solución a la Mala Práctica: Cambiará la concatenación rudimentaria por un f-string (f"El usuario {u['nombre']}..."), que es más eficiente y limpio en Python.
Mejora Técnica: Añadirá tipado estático (Type Hints) para que el código sea más profesional
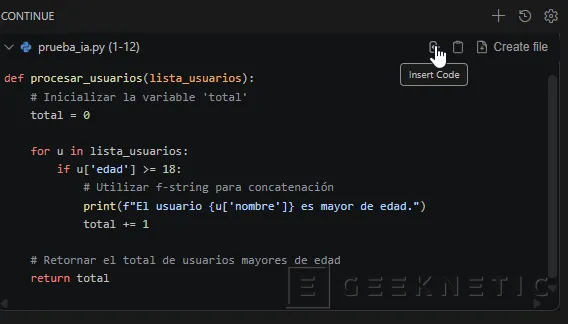
Si pasas el ratón por encima del bloque de código que te ha devuelto el chat de Continue, verás un botón que dice "Insert Code" o "Apply" (o el icono de una flecha hacia el documento). Si lo pulsas, sustituirá tu código viejo por el nuevo automáticamente.
Prueba 2: Comprobar el Autocompletado en línea
Ahora vamos a comprobar que el modelo rápido (Qwen Autocomplete 1.5B) está trabajando mientras tecleas.
Antes de empezar con la prueba nos aseguramos que otras configuraciones de Visual Code no van a entrar en conflicto. Reiniciamos el motor interno de VS Code sin cerrar la ventana:
- Vuelve a pulsar
Ctrl + Shift + P. - Escribe:
Developer: Restart Extension Hosty dale a Enter. - Verás que las extensiones se recargan por un segundo.
Con todo esto realizamos la prueba:
- Ve al final de tu archivo prueba_ia.py y crea una nueva línea.
- Empieza a escribir una función nueva para probar el código, por ejemplo, escribe despacio esto:
test_procesar_usuarios():
- En cuanto pulses Intro y dejes el cursor en la línea de abajo, espera una fracción de segundo.
- Verás que aparece un texto sombreado en gris claro sugiriéndote la creación de una lista de usuarios de prueba y la llamada a la función.
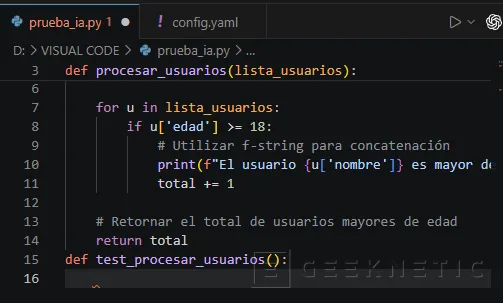
- Pulsa la tecla Tabulador para aceptar la sugerencia.
Si ambas pruebas responden correctamente (el chat te genera el código limpio y el tabulador te autocompleta las líneas) ¡Enhorabuena! Tienes tu alternativa local y privada a GitHub Copilot rindiendo al 100%.
Limitaciones que debes conocer
Las soluciones locales han avanzado enormemente, pero conviene tener expectativas realistas.
- Un modelo de 7B no compite con los mejores modelos cloud en tareas complejas de arquitectura.
- Los repositorios muy grandes pueden requerir más memoria durante la indexación inicial.
- Algunas integraciones empresariales de Copilot no tienen equivalente directo.
- La calidad del resultado depende directamente del modelo utilizado.
Aun así, para desarrollo diario, generación de código, documentación, pruebas y refactorizaciones habituales, la experiencia es sorprendentemente competitiva.
Rendimiento esperado según la GPU
|
GPU |
Chat |
Autocompletado |
Experiencia |
|---|---|---|---|
|
RTX 3060 12GB |
Fluido |
Instantáneo |
Muy buena |
|
RTX 2000 Ada 16GB |
Muy fluido |
Instantáneo |
Excelente |
|
RTX 3090 24GB |
Muy rápido |
Instantáneo |
Excelente |
|
RTX 4090 24GB |
Excelente |
Instantáneo |
Profesional |
La diferencia principal se aprecia en el chat y en tareas complejas de refactorización.
El autocompletado suele ser extremadamente rápido incluso con hardware relativamente modesto.
IA para Programar en Local
La inteligencia artificial local ha alcanzado un punto de madurez donde ya puede sustituir gran parte del trabajo que muchos desarrolladores realizan con herramientas comerciales.
Para autocompletado, refactorización, comprensión de código heredado y generación de pruebas, una combinación de Ollama, Continue y Qwen2.5-Coder ofrece una experiencia excelente manteniendo el control total sobre los datos.
Si ya dispones de un servidor con GPU, el tiempo de despliegue completo suele ser inferior a treinta minutos.
Y una vez configurado, tendrás un asistente de programación privado, personalizable y sin costes recurrentes.
Para muchos equipos, esa combinación resulta difícil de superar.
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!







