



Ejecutar IA local en Mac Mini M4
En los últimos meses ha pasado algo curioso en muchos equipos técnicos o en la "comunidad geek", los Mac Mini M4 / M4 Pro han dejado de ser “ese equipo compacto para tareas generales” y ha empezado a colarse en conversaciones sobre IA local. No por moda, sino por una mezcla bastante concreta de factores, eficiencia energética, arquitectura optimizada y, sobre todo, un cambio de mentalidad en cómo se están usando los modelos.
El resultado es bastante visible. Los tiempos de entrega de configuraciones con más memoria se han alargado, algunos distribuidores van justos de stock y, en entornos B2B, empieza a verse como una pieza más dentro del stack, no como un experimento. No es casualidad. La combinación de Apple Silicon con herramientas cada vez más maduras para inferencia local ha reducido bastante la barrera de entrada.
Ahora bien, que haya “boom” no significa que sirva para todo. Y ahí es donde conviene poner algo de contexto técnico sobre la mesa.
Por qué ahora sí tiene sentido hablar de IA local en escritorio
Durante años, ejecutar modelos fuera del cloud era poco más que una curiosidad cara y frustrante. Eso ha cambiado por tres motivos concretos:
- Cuantización de modelos. Poder ejecutar modelos de 7B o 13B parámetros en 4-bit u 8-bit ha hecho que los requisitos de memoria y cómputo sean asumibles en hardware de escritorio. Ya no necesitas una GPU de gama alta para obtener resultados útiles.
- Madurez de los frameworks. Herramientas como llama.cpp, MLX o los backends adaptados de PyTorch han mejorado mucho su soporte para Apple Silicon. Ya no estás en un entorno de segunda clase, hay optimizaciones específicas y comunidad activa detrás.
- El propio hardware. El chip M4 no destaca solo por potencia bruta, sino por cómo distribuye las cargas entre CPU, GPU y Neural Engine a través de su arquitectura de memoria unificada. Eso reduce el overhead típico al mover tensores entre componentes, que es exactamente donde los workloads de inferencia suelen perder tiempo.
Qué puedes hacer realmente con un Mac Mini M4
Aquí conviene ser concretos. Un Mac Mini M4 bien configurado, idealmente con 32 GB de RAM, puede manejar sin problemas los siguientes casos de uso:
- Inferencia de LLMs cuantizados (7B–13B parámetros)
Modelos como Qwen2.5, Mistral 7B o LLaMA 3.1 funcionan de forma fluida para generación de texto, asistentes internos o automatización de tareas. Con cuantización Q4_K_M puedes esperar entre 25 y 45 tokens/segundo en un M4 base, suficiente para uso interactivo sin esperas perceptibles.
- APIs locales con latencia controlada
Puedes exponer servicios de inferencia que responden en cuestión de milisegundos sin depender del cloud. Esto es especialmente relevante en entornos con requisitos de privacidad o compliance estricto.
- Sistemas RAG (Retrieval-Augmented Generation)
Indexar documentación interna y consultarla con un modelo local es uno de los casos de uso más sólidos hoy mismo. Pipelines con LangChain o LlamaIndex + un modelo local + ChromaDB o Qdrant funcionan bien en este hardware.
- Asistentes de desarrollo local
Autocompletado de código, generación de snippets o análisis de repositorios sin exponer el código fuente a servicios externos. Herramientas como Continue.dev o Aider pueden apuntar a un endpoint Ollama local.
- Procesamiento de texto a escala moderada
Clasificación, resumen, extracción de entidades o traducción funcionan bien para volúmenes de trabajo de una organización pequeña o mediana.
Si por precio no puedes llegar a la versión de 32GB de RAM, os dejamos una tabla de referencia rápida con respecto al resto de modelos:
| Configuración | Chip | RAM | Modelos viables | Rango tokens/seg (Q4_K_M) | Precio aprox. (ES) |
|---|---|---|---|---|---|
| Base | M4 | 16 GB | hasta 7B–8B | 28–35 tok/s | 719 € |
| Intermedia | M4 | 24 GB | hasta 13B–14B | 20–28 tok/s | 939 € |
| Alta | M4 | 32 GB | hasta 13B–14B cómodo + contextos largos | 18–26 tok/s | 1.159 € |
| Pro base | M4 Pro | 24 GB | hasta 30B | 35–50 tok/s | 1.669 € |
| Pro ampliada | M4 Pro | 48 GB | hasta 32B–70B Q4 | 20–35 tok/s | 2.309 € |
| Pro máxima | M4 Pro | 64 GB | hasta 70B Q4 con margen | 15–25 tok/s | 2.729 € |
Lo que NO deberías intentar con este Hardware
Aquí es donde muchos se llevan sorpresas desagradables.
- Entrenamiento de modelos. Ni por memoria ni por arquitectura. Puedes hacer experimentos pequeños, pero nada que se acerque a producción.
- Fine-tuning intensivo. Técnicas como LoRA ligeras son teóricamente viables, pero el M4 no es su terreno natural. Si necesitas hacer fine-tuning con regularidad, necesitas otro setup.
- Modelos sin cuantizar de gran tamaño. Un modelo de 13B sin cuantizar puede requerir más de 26 GB solo para los pesos. En cuanto añades contexto y KV cache, te vas fácilmente de la memoria disponible.
- Stacks dependientes de CUDA. Si tu pipeline asume una GPU NVIDIA como base (frameworks, librerías, código personalizado) vas a encontrar fricción o incompatibilidades directas. Metal/MPS no es un sustituto transparente de CUDA.
- Escalado horizontal. No sustituye a una infraestructura distribuida. Si necesitas servir a cientos de usuarios concurrentes, este no es el nodo.
La regla es simple, si tu caso de uso es inferencia optimizada con modelos cuantizados, encaja. Si necesitas músculo bruto o ecosistema CUDA, no.
Por qué el M4 rinde bien en Inferencia
Sin hacer ningún marketing, hay tres elementos que explican el comportamiento:
- Memoria unificada (Unified Memory Architecture): CPU, GPU y Neural Engine comparten el mismo pool de memoria física. Esto elimina las copias explícitas de tensores entre subsistemas, que en inferencia supone una reducción real de latencia y overhead. En GPUs discretas, mover datos entre RAM del sistema y VRAM es uno de los cuellos de botella habituales; aquí ese paso no existe.
- Metal Performance Shaders (MPS): Permite que frameworks como PyTorch usen la GPU de Apple de forma eficiente a través de operaciones optimizadas. No está al nivel de CUDA en ecosistema ni en madurez, pero para inferencia de modelos cuantizados la diferencia práctica es menor de lo que cabría esperar.
- Apple Neural Engine (ANE): Diseñado para operaciones matriciales de baja precisión, que es exactamente lo que domina en inferencia con modelos cuantizados. No todos los frameworks lo aprovechan directamente, llama.cpp va principalmente por CPU/GPU Metal, pero herramientas como MLX o modelos exportados a Core ML sí pueden beneficiarse de él.
El resultado no es un sistema de alta gama en términos absolutos, sino uno equilibrado que, para su tamaño y consumo (más o menos 20-30W en carga real), rinde sorprendentemente bien.
Cómo montar IA local con Ollama en Mac Mini M4
Un setup funcional, sin complicaciones, que puedes tener operativo en menos de 15 minutos:
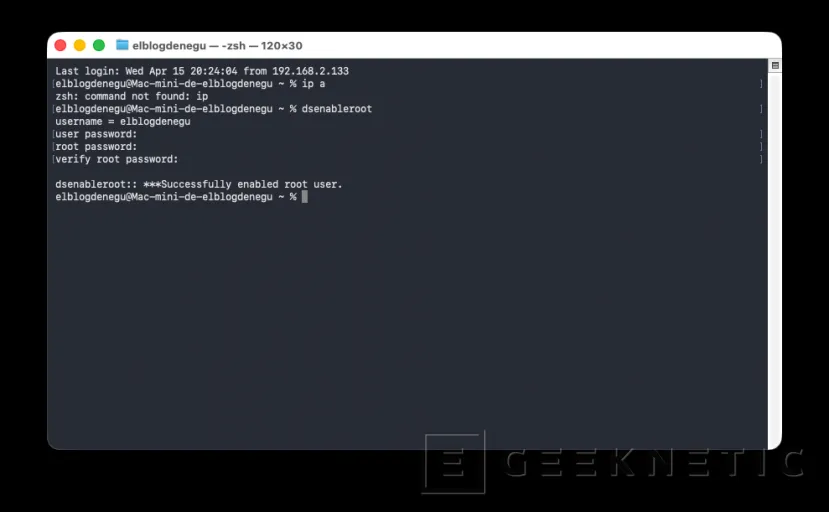
Habilitar root en Mac Mini M4
Activamos el usuario con el comando "dsenableroot":
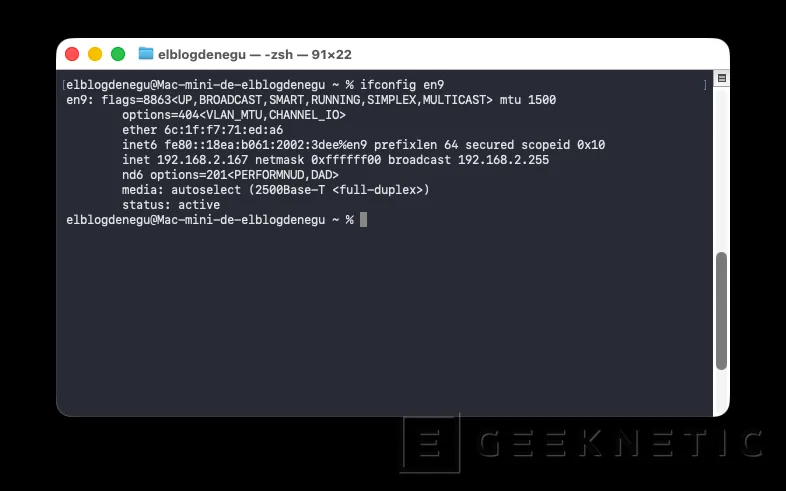
Saber la IP del equipo
Si vamos a realizar trabajos en remoto, es interesante saber la IP del equipo con el comando "ifconfig enX"
Instalar Homebrew
Para descargar paquetes instalaremos Homebrew:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"

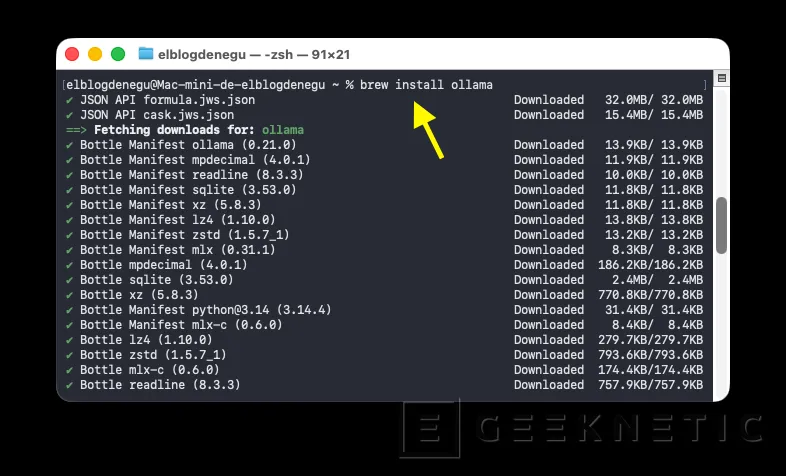
Instalar Ollama
Para el ejemplo usaremos Ollama. Lo instalamos con el siguiente comando "brew install ollama":
Arrancar Ollama
Una vez instalado arrancamos el servicio con "ollama serve":
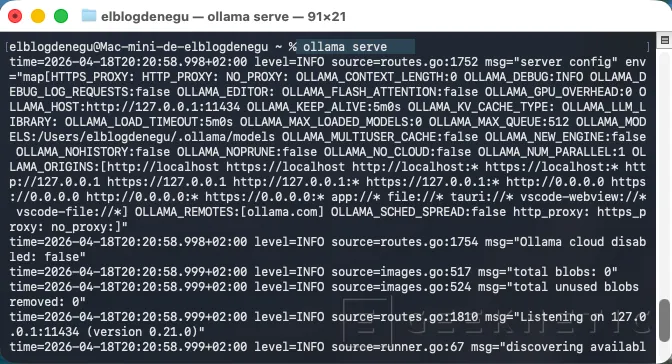
Hacemos una validación en otra consola, que realmente escucha "http://localhost:11434". Nos debería entregar un "Ollama is running":

Descarga y prueba de Modelo
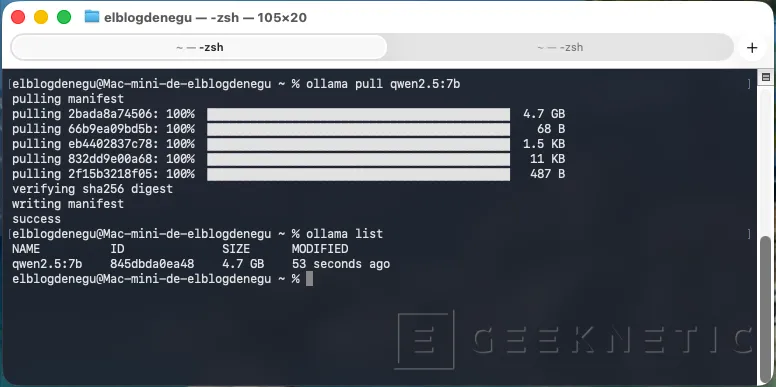
Ollama ya incluye modelos optimizados, entre ellos variantes de Qwen. Lanzamos "ollama pull qwen2.5:7b". Con "ollama list" podemos revisar el tamaño de la descarga:
Para testearlo, podemos usar: "ollama run qwen2.5:7b "Dime que cosas puedes explicarme"":
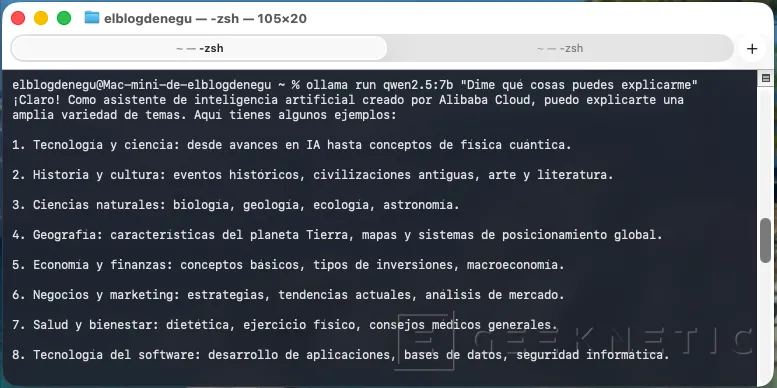
Si tenemos respuesta ya tenemos la primera piedra de nuestra IA local sobre un Mac Mini M4.
Pon el Hardware en su sitio y rendirá bien
El Mac Mini M4 no es una revolución en sí mismo. Lo que ha cambiado es el contexto en el que se usa.
Cuando lo colocas donde encaja, inferencia local, APIs internas, automatización, privacidad, sorprende. Cuando intentas forzarlo a competir en otro terreno, se queda corto de forma predecible.
La diferencia no está en el chip. Está en definir bien el problema antes de elegir el hardware.
Y eso, en entornos IT reales, suele ser lo que marca la diferencia entre un experimento y una solución que dura.
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!







